

跳表SkipList解析
- 原项目链接——基于跳表实现的轻量级键值数据库
- 添加注释后——SkipList
什么是跳表
这里不做介绍,详见:
代码解析
主要理解点
- 先来张图
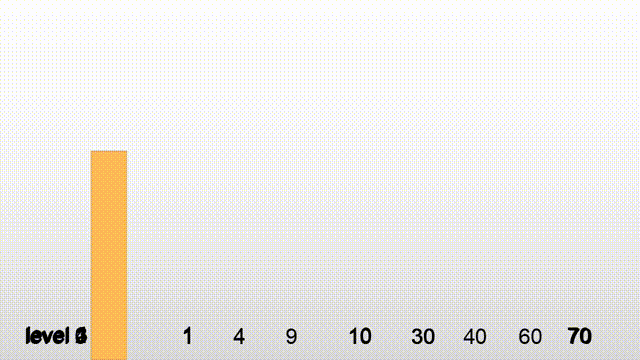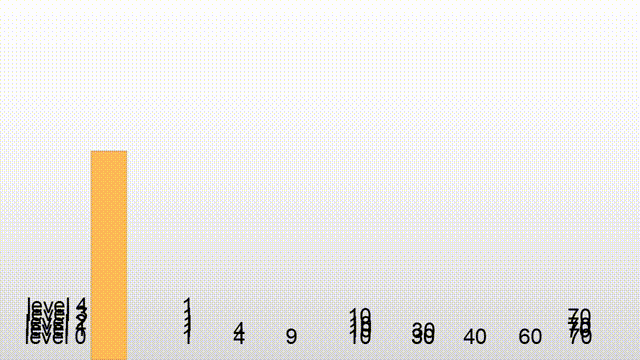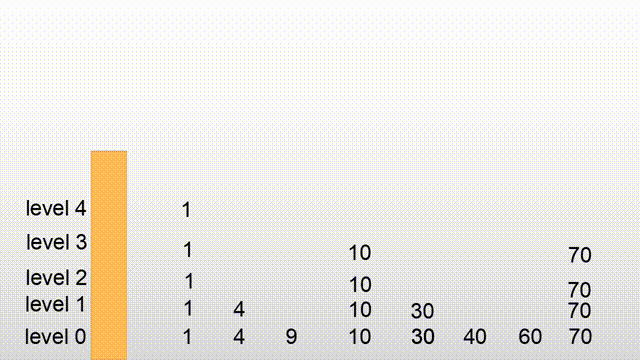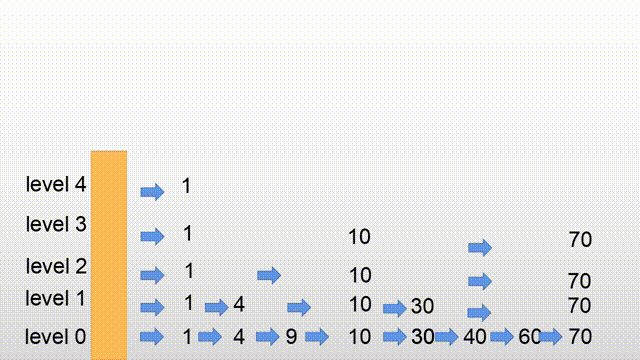
各个节点是如何相连接(关联)的?
- 通过每个节点的
forward数组,forward数组存储当前节点,在每一层的下一个节点。- 以头节点为例,头结点的forward存储的是每一层的第一个节点。然后通过第一个节点的forward[level],拿到该层的后面元素...... 以次类推,即可遍历该层所有节点。
- 与普通单链表的区别,我们可以大概理解为,上面多了几层简化的结果,如上面动画所示。
update存的是什么?
- 每层中最后一个key小于要插入节点key的节点。
节点生成的level是多少,该节点就从0层到level层一直都出现。
其它详见具体代码中的注释。
相关类&成员函数
节点类Node
template<typename K, typename V>
class Node {
public:
// 无参构造
Node() {}
// 有参构造-最后一个参数为层数
Node(K k, V v, int);
// 析构
~Node();
// 拿到当前节点key值
K get_key() const;
// 拿到当前节点value值
V get_value() const;
// 设置value值
void set_value(V);
// forward-存储当前结点在i层的下一个结点。
Node<K, V> **forward;
//所在层级
int node_level;
private:
K key;
V value;
};跳表类SkipList
template <typename K, typename V>
class SkipList {
public:
// 有参构造-参数为最大层数
SkipList(int);
// 析构
~SkipList();
// 生成随机层数
int get_random_level();
// 创建节点-最后一个参数为所在层数
Node<K, V>* create_node(K, V, int);
// 插入数据
int insert_element(K, V);
// 打印数据-每层都打印
void display_list();
// 查找元素
bool search_element(K);
// 删除元素
void delete_element(K);
// 存入文件
void dump_file();
// 加载文件
void load_file();
// 返回节点个数
int size();
private:
// 从文件中的一行读取key和value
void get_key_value_from_string(const std::string& str, std::string* key, std::string* value);
// 是否为有效的string
bool is_valid_string(const std::string& str);
private:
// 该跳表最大层数
int _max_level;
// 该跳表当前层数
int _skip_list_level;
// 跳表头节点
Node<K, V> *_header;
// 文件操作
std::ofstream _file_writer;
std::ifstream _file_reader;
// 该跳表当前的元素数
int _element_count;
};
详解insert函数
节点的插入遍历拿到update数组
Node<K, V> *update[_max_level+1];//使用_max_level+1开辟,使空间,肯定够,因为创建节点的时候,会对随机生成的key进行限制。
memset(update, 0, sizeof(Node<K, V>*)*(_max_level+1));
// 从跳表左上角开始查找——_skip_list_level为当前所存在的最高的层(一共有多少层则需要+1,因为是从level=0层开始的)
for(int i = _skip_list_level; i >= 0; i--) {//控制当前所在层,从最高层到第0层
//从每一层的最左边开始遍历,如果该节点存在并且,key小于我们要插入的key,继续在该层后移。
while(current->forward[i] != NULL && current->forward[i]->get_key() < key) {//是不是继续往后面走
current = current->forward[i]; //提示: forward存储该节点在当前层的下一个节点
}
update[i] = current;//保存
//切换下一层
}
//将current指向第0层第一个key大于要插入节点key的节点。
//下面用current用来判断要插入的节点存key是否存在
//即,如果该key不存在的话,准备插入到update[i]后面。存在,则修改该key对应的value。
current = current->forward[0];%2000_00_00-00_00_30.gif)
更新层次
// 为当前要插入的节点生成一个随机层数
int random_level = get_random_level();
//如果随机出来的层数大于当前链表达到的层数,注意:不是最大层,而是当前的最高层_skip_list_level。
//更新层数,更新update,准备在每层([0,random_level]层)插入新元素。
if (random_level > _skip_list_level) {
for (int i = _skip_list_level+1; i < random_level+1; i++) {
update[i] = _header;
}
_skip_list_level = random_level;
}
插入节点
// 创建节点
Node<K, V>* inserted_node = create_node(key, value, random_level);
// 插入节点
for (int i = 0; i <= random_level; i++) {
//在每一层([0,random_level])
//先将原来的update[i]的forward[i]放入新节点的forward[i]。
//再将新节点放入update[i]的forward[i]。
inserted_node->forward[i] = update[i]->forward[i];//新节点与后面相链接
update[i]->forward[i] = inserted_node;//新节点与前面相链接
}
//std::cout << "Successfully inserted key:" << key << ", value:" << value << std::endl;
_element_count++;//元素总数++
相关参考
- Skip List | Set 2 (Insertion)
- 什么是跳表skiplist
- 基于跳表的数据库服务器和客户端
- 以及知识星球中牲活老哥的相关分享。-跳表总结
评论区