

有限状态机
- 相关来源及参考-部分在具体模块有指明
- 《Linux高性能服务器编程》-游双
定义
- 维基百科:

在编程中
有限状态机(finite state)是服务器程序逻辑单元内部的一种高效编程方法。
- 个人理解为控制程序执行的一个变量或是一段程序,根据这个变量或是程序的有限结果进行对应的操作。
有的应用层协议头部包含数据包类型字段,每种类型可以映射为逻辑单元的一种执行状态,服务器可以根据它来编写相应的处理逻辑,如下所示代码:
STATE_MACHINE(Package _pack){
PackageType _type = _pack.GetType();
switch(_type){
case type_A:
process_package_A(_pack);
break;
case tyoe_B:
process_package_A(_pack);
break;
}
}
- 如上所示,一个简单的有限状态机,只不过其中的每种状态都是相互独立的 ,
状态之前没有相互转移,状态转移需要状态机内部驱动。- 如下所示一个带
状态转移的有限状态机示例:
STATE_MACHINE(Package _pack){
State cur_State = type_A;
while(cur_State != type_c){
PackageType _type = _pack.GetType();
switch(cur_State){
case type_A:
process_package_state_A(_pack);
cur_State = type_B;
break;
case type_B:
process_package_state_B(_pack);
cur_State = type_c;
break;
default:
break;
}
}
}
- 解释:
- 状态机先通过getNewPackage方法获得一个新的数据包,
然后根据cur_State变量的值判断如何处理该数据包,处理完整后cur_State将被赋予新的值来实现状态转移,当状态机进入下一趟循环后,它会执行新的状态对应的处理逻辑。
示例
有限状态机的一个应用实例——HTTP请求的读取和分析。
HTTP协议并未提供头部长度字段,并且头部长度的变化也很大。
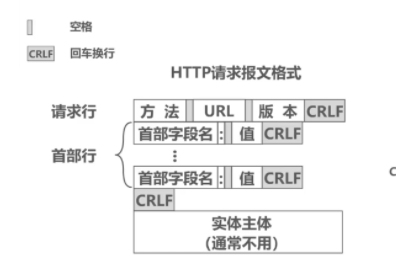
- 根据协议规定(如下图所示),我们判断HTTP头部结束的依据是遇到一个空行,该空行仅包含一对回车换行符,如果一次读操作没有读入HTTP请求的整个头部,即没有遇到空行,那么我们需要继续等待数据发送并读入。
- 每完成一次读操作,就要判断有没有空行(
空行前面是请求行和头部域),同时可以完成对整个HTTP请求头部的分析。如下代码中,我们使用主从两个状态机来实现简单的HTTP请求的读取与分析。
我们称一行HTTP请求报文为一行。
HTTP请求报文格式,图片来源——计算机网络微课堂(有字幕无背景音乐版)。
主状态机
主状态机负责进行请求行与头部字段的的判断,调用相关函数进行处理。- 在处理完请求行后,状态转移,进行处理头部字段。
- 主状态机使用checkstate来记录当前状态,初识状态为CHECK_STATE_REQUESTLINE(分析请求行),调用parse_line先获取请求行的数据,然后调用parse_requestline进行分析,之后将状态改为(
状态转义)CHECK_STATE_HEADER(头部字段分析),调用parse_line获取行数据,调用parse_headers进行解析。- 即,可以理解为,在调用parse_line解析一行数据之前,我们已经知道这行数据是什么类型的了(请求行数据or头部字段数据)。
// 主状态机-分析http请求的入口函数
HTTP_CODE parse_content( char* buffer, int& checked_index, CHECK_STATE& checkstate, int& read_index, int& start_line ){
LINE_STATUS linestatus = LINE_OK;// 从状态机状态
HTTP_CODE retcode = NO_REQUEST;
// 如果没读到头,就继续处理。
while( ( linestatus = parse_line( buffer, checked_index, read_index ) ) == LINE_OK ){// 一行一行开始解析
// 成功读全了一行, 进入到这里
char* szTemp = buffer + start_line;// start_index是在buffer中的起始位置
start_line = checked_index;// 更新下标,下一行的起始位置。
switch ( checkstate ){// 主状态机的当前状态
case CHECK_STATE_REQUESTLINE:{// 分析请求行-get/post...
retcode = parse_requestline( szTemp, checkstate );// 处理http请求的结果
if ( retcode == BAD_REQUEST ){
return BAD_REQUEST;
}
break;
}
case CHECK_STATE_HEADER:{// 分析头部字段
retcode = parse_headers( szTemp );// 每次读取到的数据是会更新的。
if ( retcode == BAD_REQUEST ){
return BAD_REQUEST;
}
else if ( retcode == GET_REQUEST )
{
return GET_REQUEST;
}
break;
}
default: // 报错
{
return INTERNAL_ERROR;
}
}
}
if( linestatus == LINE_OPEN ){// 没有读取到完整的一行
return NO_REQUEST; // 返回请求不完整
}
else{
return BAD_REQUEST;// 客户请求有语法错误
}
}从状态机
从状态机负责解析出一行的内容。
// 从状态机,用于解析出一行的内容。
LINE_STATUS parse_line( char* buffer, int& checked_index, int& read_index )
{
// read_index指向buffer中当前分析数据的下一个字节
// checked_index指向buffer中当前分析数据中正在分析的字节
// 也就是说这里分析的是checked_index~read_index中的数据
// 逐字节分析
char temp;
for ( ; checked_index < read_index; ++checked_index )
{
temp = buffer[ checked_index ];// 拿到当前要分析的字节(字符)
if ( temp == '\r' ){// 当前为\r说明可能读取到一个完整的行
/*
如果\r是当前已经读到的数据的最后一个,说明当前还没有读取到一个完整行,
需要继续读取客户端数据才能进一步分析。
*/
if ( ( checked_index + 1 ) == read_index ){
return LINE_OPEN;// 返回数据不完整
}
// 下一个就是\n,说明我们读取到了一个完整的行。
else if ( buffer[ checked_index + 1 ] == '\n' ){
buffer[ checked_index++ ] = '\0';// 添加字符串结束符
buffer[ checked_index++ ] = '\0';
// 读取到完整的一行,准备交给主状态机进行处理
return LINE_OK;// 读取到完整的一行
}
return LINE_BAD;// 否则返回当前行数据出错
}
else if( temp == '\n' ){//当前的字符是\n,说明也可能读到一个完整的行
// 进一步判断
if( ( checked_index > 1 ) && buffer[ checked_index - 1 ] == '\r' ){
buffer[ checked_index-1 ] = '\0';
buffer[ checked_index++ ] = '\0';
return LINE_OK; // 是完整行
}
return LINE_BAD;// 行出错
}
}
return LINE_OPEN;// 行数据不完整
}完整代码
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <assert.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
#define BUFFER_SIZE 4096 // 读缓冲区大小
// 主状态机的2种可能状态
enum CHECK_STATE {
CHECK_STATE_REQUESTLINE = 0, // 分析请求行
CHECK_STATE_HEADER, // 分析头部字段
//CHECK_STATE_CONTENT
};
// 从状态机的3种可能状态——行的读取状态
enum LINE_STATUS {
LINE_OK = 0, // 读取到一个完整的行
LINE_BAD, // 行出错
LINE_OPEN // 行的数据尚不完整,就是还没到/r/n的/n
};
// 服务器处理http请求的结果,
enum HTTP_CODE {
NO_REQUEST, // 请求不完整,需要继续读取客户数据
GET_REQUEST, // 获得了一个完整的客户请求
BAD_REQUEST, // 客户请求有语法错误
FORBIDDEN_REQUEST,// 客户对资源没有足够的权限访问
INTERNAL_ERROR, // 服务器内部错误
CLOSED_CONNECTION // 客户端已经关闭连接
};
// 为了简化问题,本代码没有给客户端发送一个完整的HTTP应答报文,而只是根据服务器的处理结果发送如下成功or失败信息。
static const char* szret[] = {
"I get a correct result\n",
"Something wrong\n"
};
// 从状态机,用于解析出一行的内容。
LINE_STATUS parse_line( char* buffer, int& checked_index, int& read_index )
{
// read_index指向buffer中当前分析数据的下一个字节
// checked_index指向buffer中当前分析数据中正在分析的字节
// 也就是说这里分析的是checked_index~read_index中的数据
// 逐字节分析
char temp;
for ( ; checked_index < read_index; ++checked_index )
{
temp = buffer[ checked_index ];// 拿到当前要分析的字节(字符)
if ( temp == '\r' ){// 当前为\r说明可能读取到一个完整的行
/*
如果\r是当前已经读到的数据的最后一个,说明当前还没有读取到一个完整行,
需要继续读取客户端数据才能进一步分析。
*/
if ( ( checked_index + 1 ) == read_index ){
return LINE_OPEN;// 返回数据不完整
}
// 下一个就是\n,说明我们读取到了一个完整的行。
else if ( buffer[ checked_index + 1 ] == '\n' ){
buffer[ checked_index++ ] = '\0';// 添加字符串结束符
buffer[ checked_index++ ] = '\0';
// 读取到完整的一行,准备交给主状态机进行处理
return LINE_OK;// 读取到完整的一行
}
return LINE_BAD;// 否则返回当前行数据出错
}
else if( temp == '\n' ){//当前的字符是\n,说明也可能读到一个完整的行
// 进一步判断
if( ( checked_index > 1 ) && buffer[ checked_index - 1 ] == '\r' ){
buffer[ checked_index-1 ] = '\0';
buffer[ checked_index++ ] = '\0';
return LINE_OK; // 是完整行
}
return LINE_BAD;// 行出错
}
}
return LINE_OPEN;// 行数据不完整
}
// 分析请求行-格式: GET /index.html HTTP/1.1
HTTP_CODE parse_requestline( char* szTemp, CHECK_STATE& checkstate ){
// szTemp =
// printf("test: %s\n",szTemp);
// szTemp中搜索\t,找到返回所在位置的指针
/*
一开始没有想好这个\t是什么意思,详见http请求报文。
\t就是空格
*/
char* szURL = strpbrk( szTemp, " \t" );
if ( ! szURL ){ // 请求行中没有空白字符或\t字符,则HTTP请求必有问题。
return BAD_REQUEST;// 请求中有语法错误
}
*szURL++ = '\0';// 将\t用\0覆盖,然后++指针,指向后面的内容。
// 此时szURL内容为/index.html HTTP/1.1
char* szMethod = szTemp;// 保存请求的方法,到\0会被截断。
if ( strcasecmp( szMethod, "GET" ) == 0 ){// 判断get请求
printf( "The request method is: GET\n" );
}else{
return BAD_REQUEST; // 返回请求错误
}
// 下一条请求头
// 跳过下一部分数据前面多余的空格
szURL += strspn( szURL, " \t" );
// 先拿到http版本,跳过了/index.html
char* szVersion = strpbrk( szURL, " \t" );
if ( ! szVersion ){
return BAD_REQUEST;
}
*szVersion++ = '\0';// 将\t替换为\0,
// 跳过下一部分数据前面多余的空格
// 此时szVersion = HTTP/1.1
//跳过http/1.1信息前面多余的空格
szVersion += strspn( szVersion, " \t" );
// 为什么这里没有长度限制了,因为请求行最后一段就是http版本
// 是否为http/1.1
if ( strcasecmp( szVersion, "HTTP/1.1" ) != 0 ){
return BAD_REQUEST;
}
// 回头来检查url是否合法
if ( strncasecmp( szURL, "http://", 7 ) == 0 ){
szURL += 7;
szURL = strchr( szURL, '/' );
}
if ( ! szURL || szURL[ 0 ] != '/' ){
return BAD_REQUEST;
}
//URLDecode( szURL );
printf( "The request URL is: %s\n", szURL );
// http请求行处理完毕,状态转移到头部字段分析。
checkstate = CHECK_STATE_HEADER;
return NO_REQUEST;// 当前返回NO_REQUEST无意义。
}
// 分析头部字段
HTTP_CODE parse_headers( char* szTemp ){
if ( szTemp[ 0 ] == '\0' ){// 遇到空行说明我们得到了一个正确的http请求,在头部最后,还有一个空行。
printf("test\n");
return GET_REQUEST;
}
else if ( strncasecmp( szTemp, "Host:", 5 ) == 0 ){
szTemp += 5;
szTemp += strspn( szTemp, " \t" );
printf( "the request host is: %s\n", szTemp );
}
else{// 其它头部信息
//printf( "I can not handle this header\n" );
printf("%s\n",szTemp);
}
return NO_REQUEST;
}
// 分析http请求的入口函数-从这里开始进行处理
/*
接收缓冲区
当前已经分析完了多少字节的数据
主状态机的初始状态
当前已经读取了多少字节的数据
接收缓冲区中的起始位置
*/
// 主状态机-分析http请求的入口函数
HTTP_CODE parse_content( char* buffer, int& checked_index, CHECK_STATE& checkstate, int& read_index, int& start_line ){
LINE_STATUS linestatus = LINE_OK;// 从状态机状态
HTTP_CODE retcode = NO_REQUEST;
// 如果没读到头,就继续处理。
while( ( linestatus = parse_line( buffer, checked_index, read_index ) ) == LINE_OK ){// 一行一行开始解析
// 成功读全了一行, 进入到这里
char* szTemp = buffer + start_line;// start_index是在buffer中的起始位置
start_line = checked_index;// 更新下标,下一行的起始位置。
switch ( checkstate ){// 主状态机的当前状态
case CHECK_STATE_REQUESTLINE:{// 分析请求行-get/post...
retcode = parse_requestline( szTemp, checkstate );// 处理http请求的结果
if ( retcode == BAD_REQUEST ){
return BAD_REQUEST;
}
break;
}
case CHECK_STATE_HEADER:{// 分析头部字段
retcode = parse_headers( szTemp );// 每次读取到的数据是会更新的。
if ( retcode == BAD_REQUEST ){
return BAD_REQUEST;
}
else if ( retcode == GET_REQUEST )
{
return GET_REQUEST;
}
break;
}
default: // 报错
{
return INTERNAL_ERROR;
}
}
}
if( linestatus == LINE_OPEN ){// 没有读取到完整的一行
return NO_REQUEST; // 返回请求不完整
}
else{
return BAD_REQUEST;// 客户请求有语法错误
}
}
int main( int argc, char* argv[] ){
if( argc <= 2 ){
printf( "usage: %s ip_address port_number\n", basename( argv[0] ) );
return 1;
}
const char* ip = argv[1];
int port = atoi( argv[2] );
struct sockaddr_in address;
bzero( &address, sizeof( address ) );
address.sin_family = AF_INET;
inet_pton( AF_INET, ip, &address.sin_addr );
address.sin_port = htons( port );
int listenfd = socket( PF_INET, SOCK_STREAM, 0 );
assert( listenfd >= 0 );
int ret = bind( listenfd, ( struct sockaddr* )&address, sizeof( address ) );
assert( ret != -1 );
ret = listen( listenfd, 5 );
assert( ret != -1 );
struct sockaddr_in client_address;
socklen_t client_addrlength = sizeof( client_address );
int fd = accept( listenfd, ( struct sockaddr* )&client_address, &client_addrlength );
if( fd < 0 ){
printf( "errno is: %d\n", errno );
}
else{
char buffer[ BUFFER_SIZE ]; // 接收缓冲区
memset( buffer, '\0', BUFFER_SIZE );
int data_read = 0;
int read_index = 0; // 当前已经读取了多少字节的客户数据
int checked_index = 0; // 当前已经分析完了多少字节的客户数据
int start_line = 0; // 在接收缓冲区中的起始位置
CHECK_STATE checkstate = CHECK_STATE_REQUESTLINE; // 设置主状态机的初识状态-分析请求行
while( 1 ){// 循环读取数据并进行分析
data_read = recv( fd, buffer + read_index, BUFFER_SIZE - read_index, 0 );
if ( data_read == -1 ){
printf( "reading failed\n" );
break;
}
else if ( data_read == 0 ){
printf( "remote client has closed the connection\n" );
break;
}
read_index += data_read;// 更新当前读取数据的数量
HTTP_CODE result = parse_content( buffer, checked_index, checkstate, read_index, start_line );//
if( result == NO_REQUEST ){// 继续读取数据
continue;
}else if( result == GET_REQUEST ){// 获得了一个完整的客户请求
send( fd, szret[0], strlen( szret[0] ), 0 );
break;
}else{// 错误
send( fd, szret[1], strlen( szret[1] ), 0 );
break;
}
}
close( fd );
}
close( listenfd );
return 0;
}
补充与解释
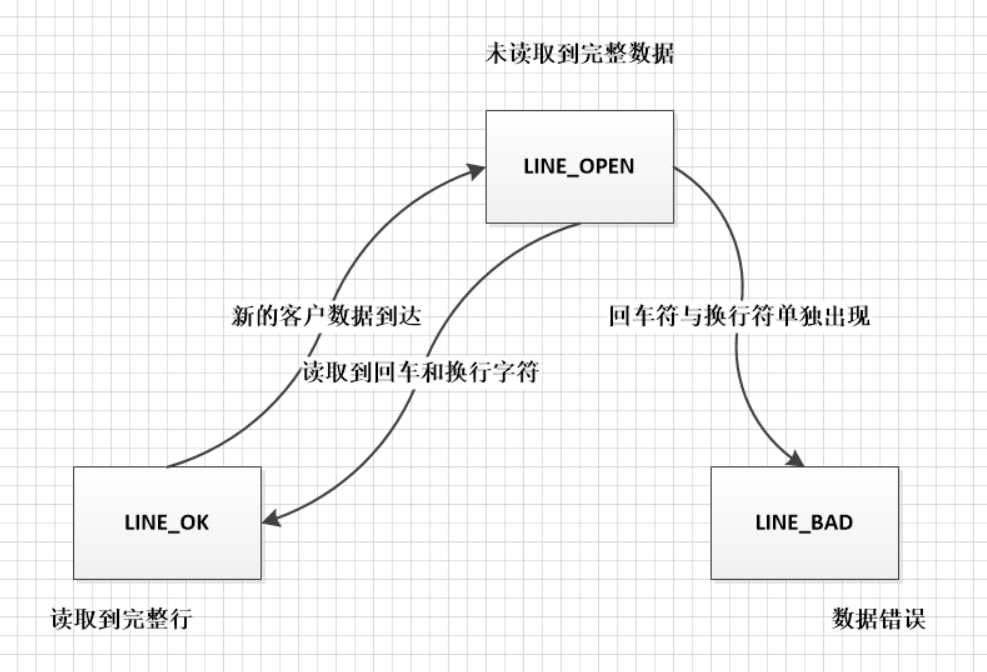
- 我们在主状态机内部调用从状态机,使用从状态机解析一行数据,其可能的状态与状态转移如下图所示:
- 使用read_index、checked_index、start_line、data_read来控制buffer中的数据读取范围。详见代码中的注释。
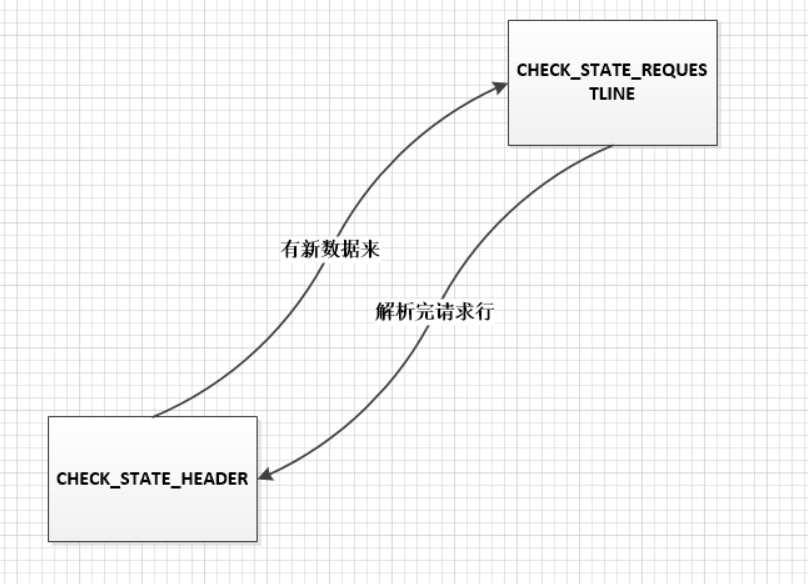
- 主状态机可能的状态以及状态转义如下图所示:
- 大致执行流程如下图所示,循环判断等详细信息并未体现。

相关函数补充
strpbrk
- 功能: 查找字符串s中第一个出现的指定字符串accept。
- 函数原型:
#include <string.h>
char *strpbrk(const char *s, const char *accept);
- 返回值: 找到返回地址,反之返回0。
- 相关参考: Linux C API 参考手册
strcasecmp
- 功能: 比较两个字符串(忽略大小写),
- 函数原型:
#include <string.h>
int strcasecmp (const char *s1, const char *s2);
- 返回值:
- 相等: 返回0.
- 不等: s1大于s2返回大于0,s1小于s2返回小于0。
- 相关参考: 百度百科
strspn
- 作用: 检索str1中第一个不在str2中出现的字符下标。
- 函数原型:
size_t strspn(const char *str1, const char *str2)
- 返回值: 返回str1中第一个不在字符串str2中出现的字符下标。
- 相关参考: 菜鸟教程
补充
- 注意字符串常量
char* test = "abcdefg";
*test = 'z'; // 是错误的,默认为字符串常量,理解为只读。
// 实际上被编译器解析为常量指针,const char* test;
// 为什么本代码中的就可以修改,因为szTemp是指向buffer的!
// 按照书写的顺序方便记忆
// const type* xx常量指针(指向常量的指针)指向的内容无法修改,但是指向的地址可以改变。
// type* const xx指针常量(指针是个常量),指向的内容可以修改,指向的地址不能改变。
/*
直接用char*创建的字符串,其实是常量指针,例如char* c1 = "test";实际上是const char* c1 = "test";无法修改其中指向的内容,要是用指针修改字符串,实际上应该为char c1[],即char类型数组,或char*指向一个char类型数组。
*/
- 通过使用指针,‘\0’进行字符串截断。
// szTemp: GET /index.html HTTP/1.1
// szTemp中搜索\t,找到返回所在位置的指针
char* szURL = strpbrk( szTemp, " \t" );
if (!szURL )return BAD_REQUEST;
*szURL++ = '\0';// 将\t用\0覆盖,然后++指针,指向后面的内容。
char* szMethod = szTemp;// 保存请求的方法,到\0会被截断。
// szMethod: GET由于多平台发布,发布后如果出现错误或是修改,可能无法及时更新所有平台内容,可在我的个人博客获取最新文章——半生瓜のblog。
评论区