

Reference & Thank & Related
- CMU15445-project1-可扩展哈希表
- 数据库——可拓展哈希(Extendable Hashing)
- 【CMU15-445数据库】bustub Project #1:Buffer Pool
- Extendible Hashing (Dynamic approach to DBMS)
Extendable Hashing
concept
什么是可扩展哈希?
Extendible Hashing is a dynamic hashing method wherein directories, and buckets are used to hash data. It is an aggressively flexible method in which the hash function also experiences dynamic changes. ——Extendible Hashing (Dynamic approach to DBMS)
- 可扩展哈希是一种动态哈希方法,其中使用目录和桶对数据进行哈希。这是一种非常灵活的方法,其中哈希函数也会经历动态变化。
主要特点:
Directories: The directories store addresses of the buckets in pointers. An id is assigned to each directory which may change each time when Directory Expansion takes place.
- 目录将桶的地址存储在指针中。 每个目录都会分配一个 ID,每次目录扩展时该 ID 都可能会发生变化。
Buckets: The buckets are used to hash the actual data.
- 桶用于散列实际数据。
members
这里以cmu15-445 2022fall p1 buffer_pool为基础讲解,以下为涉及到的成员变量。
- 全局深度globaldepth
- 当前dir_的深度大小。
- 这里的深度大小指的是: 取对应元素低多少位的二进制,用于将元素散列到不同的bucket。
- 局部深度localdepth
- 特指某个桶的深度大小
- 同上,指的就是当前该bucket所看元素二进制的位数。(ps: 每个元素低local_depth_位的二进制,肯定是相同的,才会被分到一个桶中。)
- 桶bucket_
- 真正存储元素的容器。
- 目录dir_
- 一个bucket*的数组,存储指向桶的指针,即根据元素{key,value},key的哈希值,选择对应的bucket,即散列到不同的bucket中,大小随着插入globaldepth 与localdepth 大小关系进行扩容。详见下方说明
- 要注意的是,dir _ 的大小和bucket桶的数量并不是一直对等的。因为同一个桶可能会被多个dir_指向。
Insert
下面开始进行插入元素函数的介绍,也仅仅介绍这一个函数。
- 首先创建可扩展哈希,完成初始化(bucket的大小,local_depth,global_depth的大小)。
- 插入元素,根据哈希函数,求得指向要映射桶的指针,即dir_[i],判断当前所指向bucket是否已经满了,没满,直接插入即可;
- 反之,桶满了,判断当前globaldepth 和桶的 local depth 的 大小关系。这个过程需要不断重复,直到元素可以顺利插入。
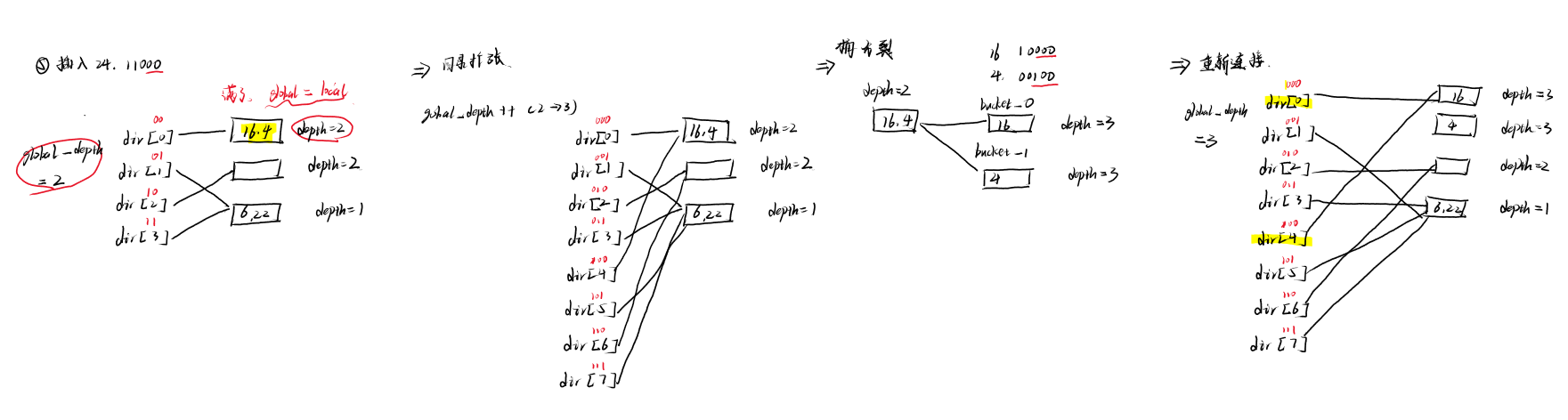
- 如果global depth 等于local depth ,需要进行桶分裂和目录扩张。
- 目录扩张:
- 目录扩张就是将当前的目录dir 大小翻倍,同时全局深度global depth_++。
- 将原来的dir_ 在后面再push_back一遍。使得同一个bucket被重复指向。
- 进一步理解,为什么扩展后,"两个"dir可以指向同一个bucket?我们会发现,当完成桶分裂后进行重新连接,这两个dir会根据二进制某位的不同,分别指向这两个bucket,之后同理。
- 区分这两个bucket中元素的不同,就是根据某一位二进制,即,对应的dir_索引的二进制位。(带着这个想法,去看下方的插入示例),这个两个二进制位分别与那两个dir 索引对应的二进制位相同。
- 桶分裂:
- 桶分裂就是将当前这个满了的bucket重新进行散列到两个新桶中,通过再往左判断一个二进制位拆分(详见下方示例),这两个新桶的depth在原来的基础上+1,即通过1<<local_depth与哈希值按位与。
- 如果global depth 大于local depth,则,仅仅需要进行桶分裂即可。
example
下面以插入这几个数为例,其中元素仅仅声明了key,并未标注对应的value,因为是根据key进行插入,以及查找等操作的,在下面的示例中, 你也可以理解为key == value。
- 初始化

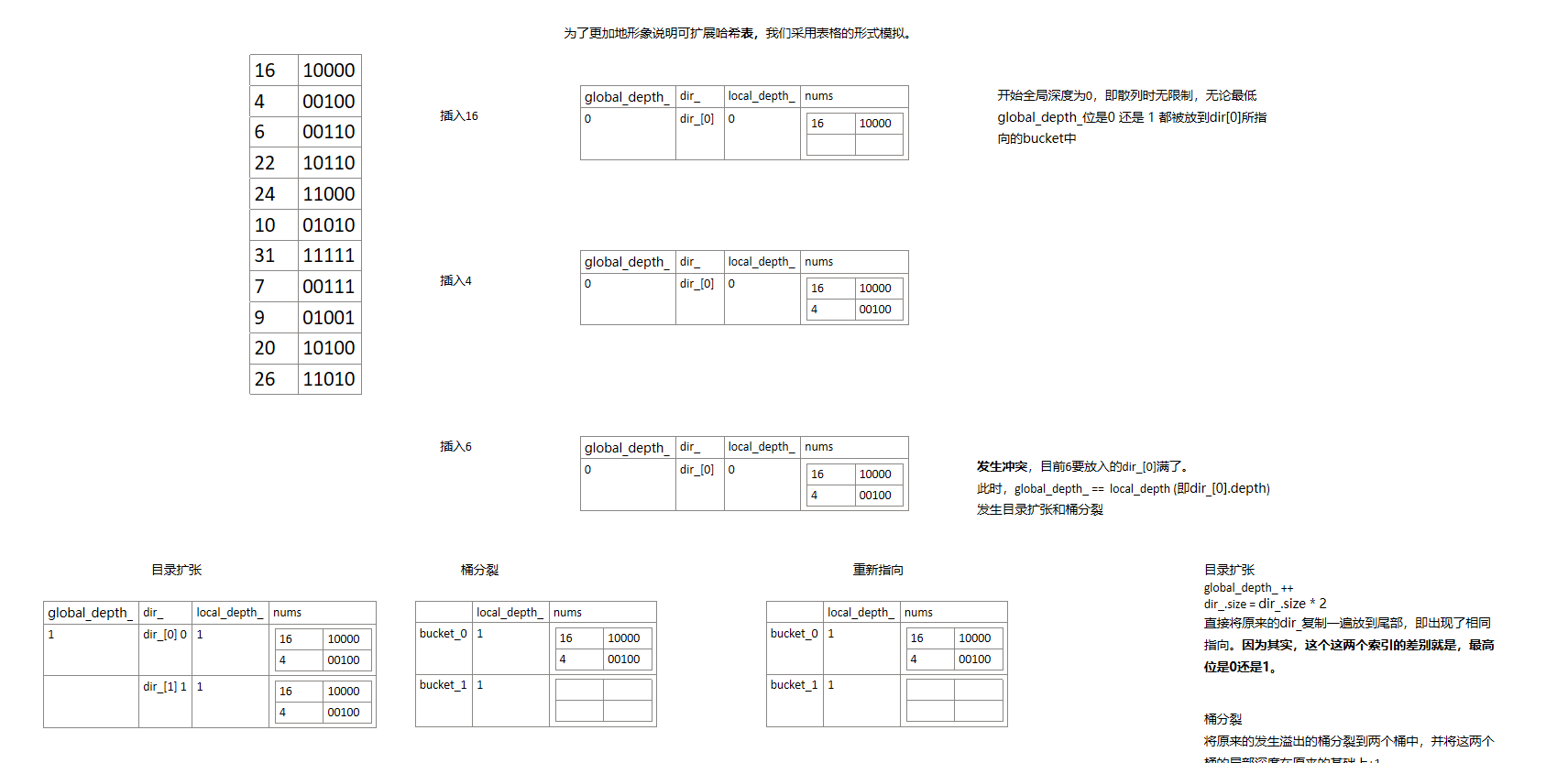
- ①插入16
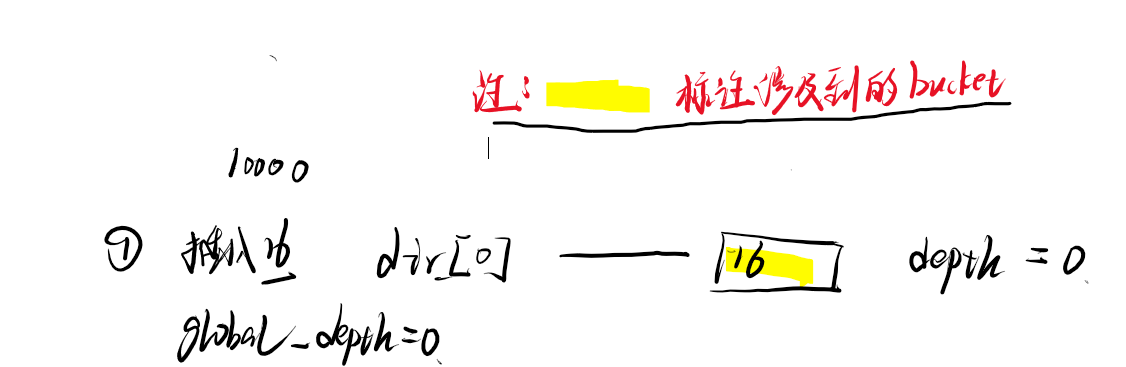
- ②插入4
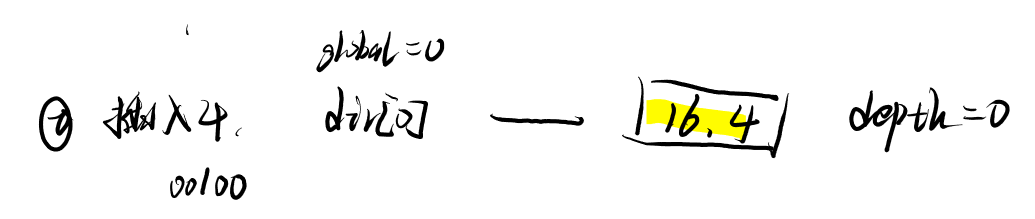
- ③插入6
发生溢出,判断global depth 与发生溢出的桶的depth_大小关系。如下图所示,二者相等,依次进行->目录扩张->桶分裂->重新连接
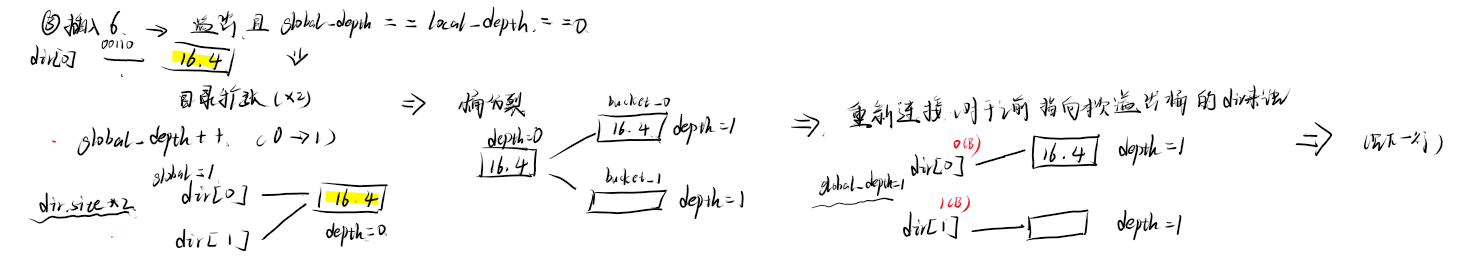
再次尝试插入6,还是溢出,再进行判断。

又尝试插入6,此时完成插入。
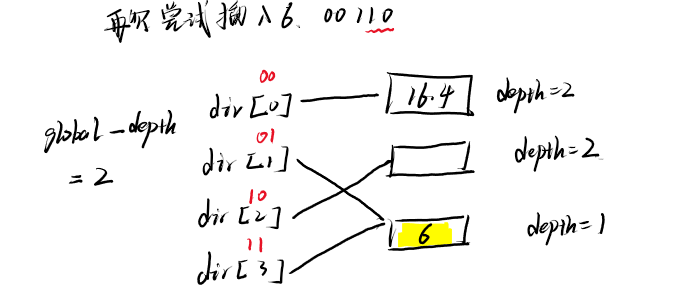
相关内容补充

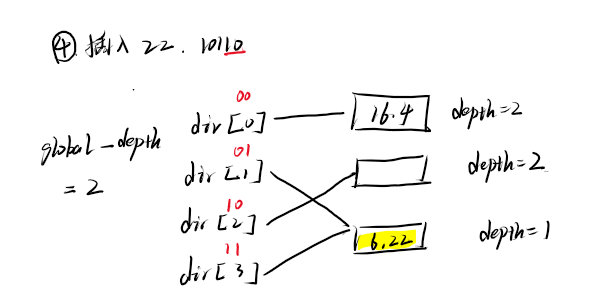
- ④插入22
- ⑤插入24
发生溢出
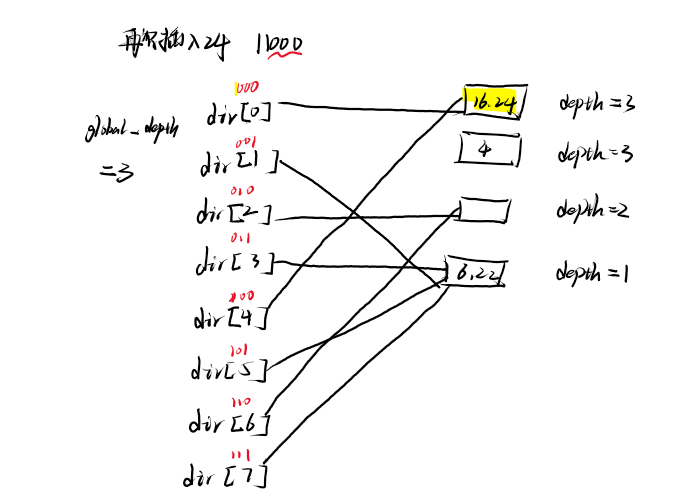
再次尝试插入24
- ⑥插入10

完成插入,后面越插入越复杂了,所以就到此为止了,注意: 不同的初始条件,插入元素得到的结果不同。
- 实际上我们要插入元素的key并不都是整型,具体实现中我们会通过其中的hash函数求得对应key的哈希值来进行散列。
Q & A
有关桶分裂后的重新指向问题
详见上方插入过程中,有一段红字标注。
- 即,一个桶分裂到两个桶,根据一位二进制位是0还是1,同样的,多个指向同一个bucket的dir[i]重新指向,也需要判断桶分裂区分的那位二进制位,对应目录索引的二进制是0还是1。原来指向同一个桶的dir[i],它们索引i的对应二进制位,此位的右边所有位是相同的。
- 根据这个意思,自己模拟一下插入,就可以理解了。
Complement
vector 的 resize 与 reserve 区别
- resize方法会改变vector的大小,如果的新的大小比原来的更大,则会在vector末尾添加元素,调用默认构造函数。
- reserve只会预分配空间,即调整capacity的大小,但是如果reserve()的参数值小于当前size的大小,vector的容量并不会发生变化,capacity在任何时候,容量都是大于等于size
代码示例
#include <iostream>
#include <algorithm>
#include <cstring>
#include <vector>
using namespace std;
class A{
public:
A(){
cout <<"structure"<<endl;
m_d = 999;
}
~A(){
cout <<"distructure"<<endl;
}
int m_d;
};
int main(void){
vector<A>v1;
vector<A>v2;
// 给一个比当前元素数量大的数
v1.resize(2);// 调用A默认构造,插入v1尾部
cout << "v1 capacity: "<<v1.capacity()<<endl; // 2
cout << "v1 size: "<<v1.size();// 2
cout <<endl;
v1[0].m_d = 0;
v1[1].m_d = 1;
v2.reserve(2);
cout << "v2 capacity: "<<v2.capacity()<<endl;// 2
cout << "v2 size: "<<v2.size();// 2
cout <<endl;
// 给一个比当前元素数量小的数,测试是否能删除调用析构函数,
v2.push_back(A());// 给v2两个
v2.push_back(A());
cout <<"test distructure"<<endl;
v1.resize(1);
v2.reserve(1);// reserve一个比当前小的值,容量不会变化
cout << "v1 capacity: "<<v1.capacity()<<endl; // 2
cout << "v1 size: "<<v1.size();// 1
cout <<endl;
cout << "v2 capacity: "<<v2.capacity()<<endl;// 2
cout << "v2 size: "<<v2.size();// 2
cout <<endl;
cout << v1[1].m_d<< endl;// vector的[]并没有越界访问判断
system("pause");
return 0;
}Last
- (PS: 本来开始用表格画图的,后来越画越乱,中间错了几次,于是就放弃了o(╥﹏╥)o,感兴趣的小伙伴可以试下。)
- 代码实现的时候参考了github搜到的一个老哥的实现,感谢老哥分享,但是出于课程要求,我就不贴链接啦~
评论区