

回溯算法
- 《代码随想录》
- 什么是回溯算法?
- 回溯算法也可以叫做回溯搜索法,它是一种搜索方式。
- 回溯是递归的副产品,只要有递归就会有回溯。
- 回溯法的效率:
- 回溯法的本质是穷举,穷举所有可能,然后选出我们想要的答案。(n层for循环嵌套)
- 如果想让回溯法更高效一些,可以加一些剪枝操作,但也无法改变回溯法就是穷举的本质。
- 回溯法一般可以解决如下几种问题:
- 组合问题: N个数里面按一定规则找出K个数的集合
- 切割问题: 一个字符串按一定规则由于几种切割方式
- 子集问题: 一个N个数的集合里有多少符合条件的子集
- 排列问题: N个数按一定规则全排列,有几种排列方式。
- 棋盘问题: N皇后,解数独等
- 如何理解回溯法?
- 回溯法解决的都可以抽象为树型结构。
- 因为回溯法解决的都是在集合中递归查找子集,集合的大小就构成了树的宽度,递归的深度构成了树的深度。
- 递归要有终止条件,所以必然是一棵高度有限的树(N叉树)
- 回溯模板
- for循环横向遍历,递归 纵向遍历,回溯不断调整结果集。
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
// for循环-横向遍历
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归-纵向遍历
回溯,撤销处理结果
}
}
- 性能分析
- 组合问题分析
- 时间复杂度: $O(n* 2^n)$
- 组合问题其实就是一种子集问题,所以组合问题最坏的情况,也不会超过子集问题的时间复杂度。
- 空间复杂度: $O(n)$
- 和子集问题同理。
- 子集问题分析
- 时间复杂度: $O(n * 2^n)$
- 每种元素状态无非选与不选,所以时间复杂度为&O(2^n)$;
- 构造每一组子集都需要填进数组,又需要$O(n)$;
- 所以最终时间复杂度为: $O(n*2^n)$
- 空间复杂度: $O(n)$
- 递归深度为n,所以系统栈所用空间为$O(n)$
- 每一层递归所用的空间都是常数级别,注意代码里的result和path都是全局变量,就算是放在参数里,传引用,并不会重新申请内存。
- 排列问题
- 时间复杂度: $O(n!)$
- 这个可以从排列的树形图中很明显发现,每一层节点为n,第二层每一个分支都延伸了n-1个分支,再往下又是n-2个分支,所以一直到叶子节点一共就是 n n-1 n-2 * ..... 1 = n!。每个叶子节点都会有一个构造全排列填进数组的操作(对应的代码:result.push_back(path)),该操作的复杂度为$O(n)$。
- 所以,最终时间复杂度为:n * n!,简化为$O(n!)$。
- 空间复杂度: $O(n)$
- 和子集问题同理。
77. 组合
- 回溯法的经典题目
- 图解如下图所示:

class Solution {
public:
vector<int>path;// 选取的组合
vector<vector<int>>ret;// 最终结果
// 用startIndex来记录下一层递归搜索的起始位置
// 防止重现重复的组合
void backtracking(int n ,int k ,int startIndex){
if(path.size() == k){
ret.push_back(path);// 收集结果
return ;
}
for(int i = startIndex;i <= n;i++){// 横向遍历
path.push_back(i);// 添加
backtracking(n,k,i+1);// 纵向遍历
path.pop_back();// 撤销
}
}
vector<vector<int>> combine(int n, int k) {
backtracking(n,k,1);
return ret;
}
};
- 剪枝优化,将for循环控制条件改为
class Solution { public: vector<int>path;// 选取的组合 vector<vector<int>>ret;// 最终结果 // 用startIndex来记录下一层递归搜索的起始位置 // 防止重现重复的组合 void backtracking(int n ,int k ,int startIndex){ if(path.siz)e() == k){ ret.push_back(path);// 收集结果 return ; } // 如果for循环选择的起始位置之后的元素个数 已经不足 我们需要的元素个数了,那么就没有必要搜索了。 for (int i = startIndex; i <= n - (k - path.size()) + 1; i++){ // i为本次搜索的起始位置 path.push_back(i);// 添加 backtracking(n,k,i+1);// 纵向遍历 path.pop_back();// 撤销 } } vector<vector<int>> combine(int n, int k) { backtracking(n,k,1); return ret; } };
216.组合总和III
- 模板题,在上一题的基础上,在收集结果的时候增加是否等于目标值的判断。
class Solution {
public:
vector<int>path;
vector<vector<int>>ret;
void backtracking(int k, int n,int startIndex){
if(path.size() == k){
// 满足指定和才收集
if(accumulate(path.begin(),path.end(),0) == n)ret.push_back(path);
return ;
}
for(int i = startIndex;i <= 9;i++){
path.push_back(i);
backtracking(k,n,i+1);
path.pop_back();
}
}
vector<vector<int>> combinationSum3(int k, int n) {
backtracking(k,n,1);
return ret;
}
};
- 优化剪枝
class Solution {
public:
vector<int>path;
vector<vector<int>>ret;
void backtracking(int k, int n,int startIndex){
if(path.size() == k){
// 满足指定和才收集
if(accumulate(path.begin(),path.end(),0) == n)ret.push_back(path);
return ;
}
for(int i = startIndex;i <= 9-(k-path.size())+1;i++){// 剩余元素个数不足了,终止
path.push_back(i);
if(accumulate(path.begin(),path.end(),0) > n){// 已经大于目标值了,剪掉
path.pop_back();
return;
}
backtracking(k,n,i+1);
path.pop_back();
}
}
vector<vector<int>> combinationSum3(int k, int n) {
backtracking(k,n,1);
return ret;
}
};17. 电话号码的字母组合
- 注意题目的意思是,根据这几个数字所对应的字母进行组合。几个数字,每个组合就有几个元素。
- 从每个数字对应的元素中取一个。然后组合。
- 与上面题的不同,本体每一个数字代表的是不同的组合,也就是求不同集合之间的组合,而上面两道题,都是都同一个集合中的组合。
class Solution {
public:
string path;
vector<string>ret;
const string letterMap[10] = {
"", // 0
"", // 1
"abc", // 2
"def", // 3
"ghi", // 4
"jkl", // 5
"mno", // 6
"pqrs", // 7
"tuv", // 8
"wxyz", // 9
};
void backtracking(const string& digits,int index){
if(index == digits.size()){// 每个数字对应的字母都取了一个,收集。
ret.push_back(path);;
return;
}
int digit = digits[index]-'0';//将对应char转为int
string letters = letterMap[digit];
for(int i = 0; i< letters.size();i++){
path.push_back(letters[i]);
backtracking(digits,index+1);
path.pop_back();
}
}
vector<string> letterCombinations(string digits) {
if(digits.size() == 0)return ret;
backtracking(digits,0);
return ret;
}
};
- 隐藏回溯细节
- 增加参数s,每次修改仅在调用递归函数传参时修改,递归结束返回回来,原值并未被修改。从而达到回溯效果。
class Solution {
public:
const string letterMap[10] = {
"", // 0
"", // 1
"abc", // 2
"def", // 3
"ghi", // 4
"jkl", // 5
"mno", // 6
"pqrs", // 7
"tuv", // 8
"wxyz", // 9
};
vector<string>ret;
void backtracking(const string& digits,string s,int index){// 增加参数string
if(index == digits.size()){
ret.push_back(s);
return ;
}
int digit = digits[index]-'0';
string leeters = letterMap[digit];
for(int i =0; i < leeters.size();i++){
backtracking(digits,s+leeters[i],index+1);// 回溯
}
}
vector<string> letterCombinations(string digits) {
if(digits.size() == 0)return ret;
string s;
s.clear();
backtracking(digits,s,0);
return ret;
}
};39. 组合总和
- 注意题目要求,所有元素不限制选取次数。在我们实际的代码中,要修改模板的控制下标。
>- 方法1: 需要排序,因为按顺序取,需要判断是否超出目标值,超过则终止当前层的选取——剪枝。
class Solution {
public:
vector<vector<int>>ret;
vector<int>path;
void backtracking(vector<int>& candidates,int target,int startIndex){
if(accumulate(path.begin(),path.end(),0) == target){
ret.push_back(path);
return ;
}
for(int i = startIndex; i < candidates.size();i++){
path.push_back(candidates[i]);
if(accumulate(path.begin(),path.end(),0) > target){// 在这里终止,因为是排序过了,后面的只会更大。所以终止选取。
path.pop_back();
return;
}
backtracking(candidates,target,i);// 不加1,重复当前值
path.pop_back();
}
// 或者
// for(int i = startIndex; i < candidates.size() && accumulate(path.begin(),path.end(),0) < target;i++){
// path.push_back(candidates[i]);
// backtracking(candidates,target,i);
// path.pop_back();
// }
}
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
sort(candidates.begin(),candidates.end());// 注意排序
backtracking(candidates,target,0);
return ret;
}
};
- 方法2: 无序排序,递归后,收集结果前判断,是否超过目标,超过目标值终止计算,返回,继续选取下一个值。因为没排序,后面可能还有符合条件的。
注意对比与方法1终止条件位置的不同。
class Solution {
public:
vector<vector<int>>ret;
vector<int>path;
void backtracking(vector<int>& candidates,int target,int startIndex){
if(accumulate(path.begin(),path.end(),0) > target){// 超过目标值则回退,不要再选啦。
return ;
}
if(accumulate(path.begin(),path.end(),0) == target){
ret.push_back(path);
return ;
}
for(int i = startIndex; i < candidates.size();i++){
path.push_back(candidates[i]);
backtracking(candidates,target,i);
path.pop_back();
}
}
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
backtracking(candidates,target,0);
return ret;
}
};
- 错误提示:
- 参数startIndex,传递的时候不同于上面的两题,而是传入当前收集的值的下标,i,不是i+1,为了继续重复选取当前元素。
- 开始我每次传的都是0,这样会造成重复的组合。
40.组合总和II
- 在上一题的基础上增加去重
- 去重1: 使用startIndex去重
class Solution {
public:
vector<int>path;
vector<vector<int>>ret;
void backtracking(vector<int>& candidates,int target,int stratIndex){
if(accumulate(path.begin(),path.end(),0) == target){
ret.push_back(path);
return ;
}
for(int i = stratIndex;i < candidates.size();i++){
// 去重
if(i > stratIndex && candidates[i] == candidates[i-1])continue;
path.push_back(candidates[i]);
if(accumulate(path.begin(),path.end(),0) > target){
path.pop_back();
return;
}
backtracking(candidates,target,i+1);
path.pop_back();
}
}
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
sort(candidates.begin(),candidates.end());
backtracking(candidates,target,0);
return ret;
}
};
- 使用used数组去重——
下面的90题子集II有更详细的去重解释。
- 同一个树枝上的元素可以重复,同一个树层上的元素不可以重复。去的就是同一个树层的重。
- 详见代码中的注释。
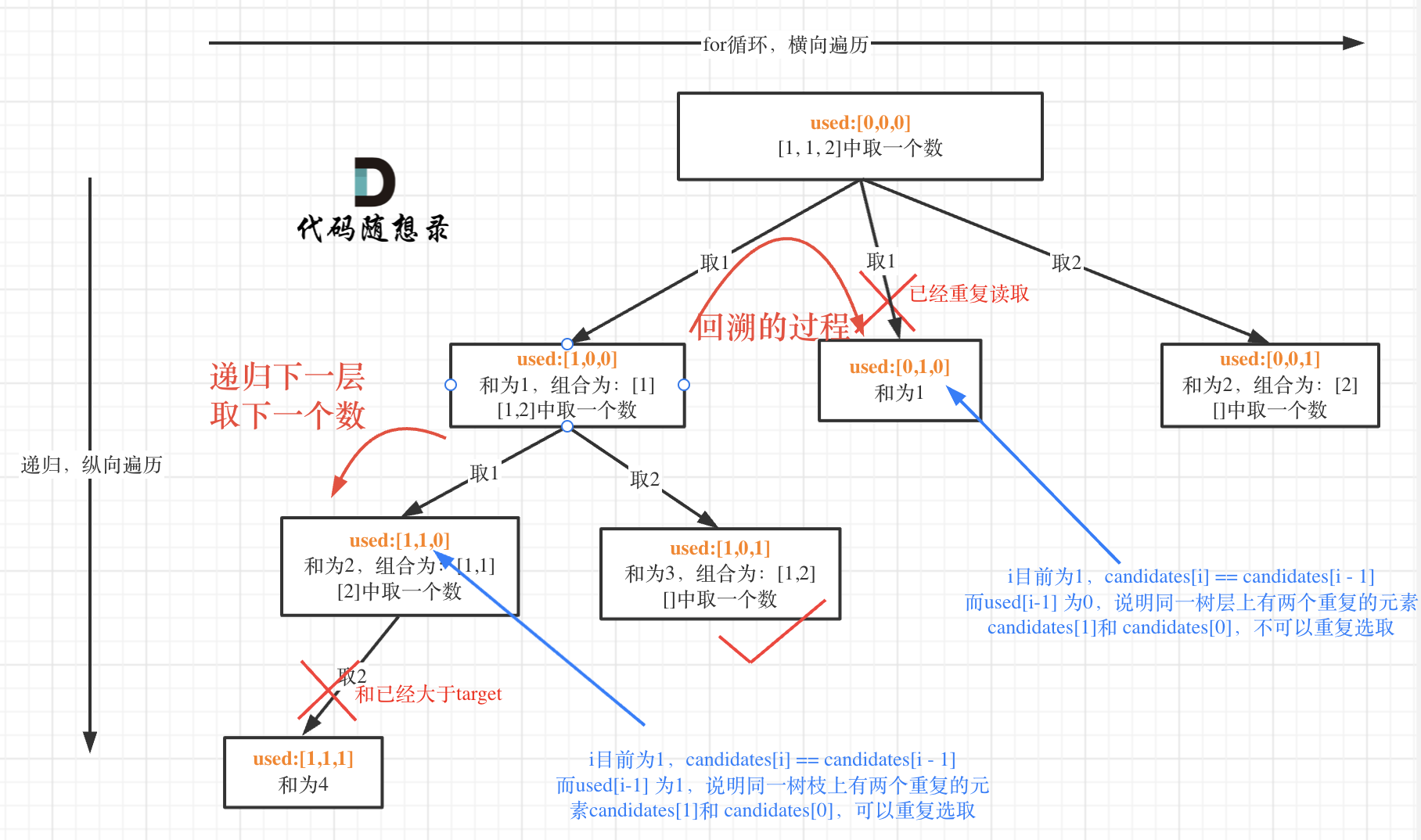
class Solution {
public:
vector<int>path;
vector<vector<int>>ret;
void backtracking(vector<int>& candidates,int target,int stratIndex,vector<bool>&used){
if(accumulate(path.begin(),path.end(),0) == target){
ret.push_back(path);
return ;
}
for(int i = stratIndex;i < candidates.size();i++){
// 去重,跳过同一层使用过的元素
// used[i-1] == true,表明同一个树枝candiates[i-1]使用过——联想往下纵向遍历。
// used[i-1] == false,表明同一个树层candiates[i-1]使用过——联想往右横向遍历。
// 为什么? used[i-1] == false;
// 因为,同一树层,used[i-1] == false才能表示,当前取的candidates[i]是从candidates[i-1]回溯而来。
// used[i-1] == true 说明进入下一层递归,向下纵向遍历,同一个树枝上使用过啦。
// 与前一个元素与当前元素相等,并且在同一个树枝使用过,去掉。
if(i > 0 && candidates[i] == candidates[i-1] &&
used[i-1] == false)continue;
path.push_back(candidates[i]);
if(accumulate(path.begin(),path.end(),0) > target){
path.pop_back();
return;
}
used[i] = true;// 树枝使用了,遍历
backtracking(candidates,target,i+1,used);
used[i] = false;
path.pop_back();
}
}
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
sort(candidates.begin(),candidates.end());
vector<bool>used(candidates.size(),false);
backtracking(candidates,target,0,used);
return ret;
}
};131.分割回文串
- 可以说是回溯模板题,只是收集结果方式有所不同,判断从某一位置截取到当前位置的字串是否为回文字串, 是则收集。
class Solution { public: // 判断是否为回文子串-双指针 bool isPalindrome(const string& s,int start,int end){ for(int i = start,j = end; i < j;i++,j--){ if(s[i] != s[j])return false; } return true; } vector<vector<string>>ret; vector<string>path; void backtracking(const string& s, int startIndex){ if(startIndex >= s.size()){// 收集一轮结果 ret.push_back(path); return ; } for(int i = startIndex;i < s.size();i++){ // 想象了一下搜索过程,每次递归刚进入先选一个字母,直到最后,然后开始返回,倒数第二次选两个,依次回溯调整选取状态...其中要判断每次选取的子串是否为回文子串。 if(isPalindrome(s,startIndex,i)){// 是回文字串 string str = s.substr(startIndex,i-startIndex+1); path.push_back(str);// 收集 }else continue;//不是回文字串 backtracking(s,i+1);// 切割的地方不能重复切割,所以传入i+1 path.pop_back();// 回溯 } } vector<vector<string>> partition(string s) { backtracking(s,0); return ret; } };- 优化,提前计算出某一个子串是否是回文字串。dp思想。
- 具体来说, 给定一个字符串s, 长度为n, 它成为回文字串的充分必要条件是s[0] == s[n-1]且s[1:n-1]是回文字串。
class Solution { public: vector<vector<string>>ret; vector<string>path; vector<vector<bool>>isPalindrome; void backtracking(const string& s, int startIndex){ if(startIndex >= s.size()){// 收集一轮结果 ret.push_back(path); return ; } for(int i = startIndex;i < s.size();i++){ if(isPalindrome[startIndex][i]){// 是回文字串 string str = s.substr(startIndex,i-startIndex+1); path.push_back(str);// 收集 }else continue;//不是回文字串 backtracking(s,i+1); path.pop_back();// 回溯 } } // 计算每个子串是否为回文字串 void computePalindrome(const string& s){ isPalindrome.resize(s.size(),vector<bool>(s.size(),false)); for(int i = s.size()-1;i >= 0;i--){ for(int j = i;j < s.size();j++){ if(j ==i)isPalindrome[i][j] = true; else if(j - i == 1)isPalindrome[i][j] = (s[i] == s[j]); else isPalindrome[i][j] = (s[i]==s[j] && isPalindrome[i+1][j-1]); } } } vector<vector<string>> partition(string s) { computePalindrome(s); backtracking(s,0); return ret; } };
93.复原IP地址
- 同上切割问题,可以使用回溯搜索法把所有可能性搜出来。
class Solution { public: vector<string>ret; bool isValid(const string& s,int start,int end){ if(start > end)return false; if(s[start] == '0' && start != end)return false;// 前导0,不合法 int num = 0; for(int i = start;i <= end;i++){ if(s[i] > '9' || s[i] < '0'){// 非数字 return false; } // 从前往后遍历一个数转成整型 num = num* 10 + (s[i]-'0'); if(num > 255)return false; } return true; } void backtracking(string& s,int startIndex,int pointCount){ if(pointCount == 3){ if(isValid(s,startIndex,s.size()-1)){// 判断最后一段是不是合法的 ret.push_back(s);// 在原字符串上修改 } return ; } for(int i = startIndex;i < s.size();i++){ if(isValid(s,startIndex,i)){// 判断这个区间子串是否合法 s.insert(s.begin()+i+1,'.');// 在当前这个数字后面插入一个. pointCount++; backtracking(s,i+2,pointCount);// 注意,新加了一个点,所以要加2,到下一个数字 pointCount--; s.erase(s.begin()+i+1);// 删除插入的点 }else break;//不合法直接结束 } } vector<string> restoreIpAddresses(string s) { if(s.size() < 4 || s.size() > 12)return ret;// 剪枝 backtracking(s,0,0); return ret; } };
78.子集
- 方法1: 使用一个used数组来标记是否使用当前元素,0-暂时不考虑,1-使用,2-不使用。
class Solution {
public:
vector<int>used;// 记录是否使用过
vector<vector<int>>ret;
void backtracking(vector<int>& nums,int startIndex){
if(startIndex == nums.size()){// 到达边界出,开始收集结果
vector<int>path;
for(int i = 0; i < nums.size();i++){
if(used[i] == 1)path.push_back(nums[i]);
}
ret.push_back(path);
return;
}
// startIndex当前位置
used[startIndex] = 1;// 选当前位置
backtracking(nums,startIndex+1);
used[startIndex] = 0;// 恢复成未考虑状态
used[startIndex] = 2;// 不选当前位置
backtracking(nums,startIndex+1);
used[startIndex] = 0;// 恢复成未考虑状态
}
vector<vector<int>> subsets(vector<int>& nums) {
used.resize(nums.size(),0);
backtracking(nums,0);
return ret;
}
};
- 方法2: 相对于方法2来说,方法1更直观一些。
- 可结合下图理解,当前元素,选与不选的这个过程。
- startIndex既是边界,也是当前要操作的元素。
- 方法1,是通过使用used数组来标记当前元素(startIndex下标所对应的元素)选还是不选,最后到达边界,遍历原数组,统一收集结果path,在放入最终结果集ret中。
- 方法2,则是将选的元素直接收集进path数组中,不选了,也就是回溯,再将其pop出来,此时不断移动边界startIndex直至到达边界。到达边界后,再将小数组path放进结果集ret中。

class Solution {
public:
vector<int>path;
vector<vector<int>>ret;
void backtracking(vector<int>& nums,int startIndex){
ret.push_back(path);// 收集结果
if(startIndex == nums.size())return ;// 此终止条件可以省略
for(int i = startIndex;i < nums.size(); i++){
path.push_back(nums[i]);// 选上当前元素
backtracking(nums,i+1);// 递归
path.pop_back();// 回溯-不选当前元素啦
}
}
vector<vector<int>> subsets(vector<int>& nums) {
backtracking(nums,0);
return ret;
}
};90. 子集 II
- 开始没想明白这跟上面那个题有什么区别,我说上面那个没说不让重复不也没重吗,其实不对,因为上面那个给的数据就不是重复的,所以求子集没重复,这题给的数据出现重复的元素了,所以就需要增加一个去重操作。
相当于40题组合总和II中,我们使用的used数组,是一个意思,但是我觉得那样的意思容易让人弄混,容易直译数组名used的含义,所以我们这里将其改为int型数组,1表示当前树枝上使用了,2表示当前树层上使用了,0表示暂未考虑。
- 上方划线文字作废,就按照true表示当前树枝使用过,false表示当前树层使用过就行。
- 如下方图解所示,理解起来稍微有一点抽象,可以画图走一遍,下图仅给出第一次选1的分支。

- 仔细想一下,其实不难。
- 就是先确定一点,即,这个树枝上第一个元素,我们称为"父亲",然后再往后选剩下的每一个数,即"孩子"
- 重复的情况就是,当前这个元素上当前这个元素和前一个元素相同,并且前一个元素不是父亲元素(i > 0),——说明,当前父亲和孩子的组合,出现过了,就是重复啦,去掉。
- 那你可能就问了,那后面也是重复的吗,当然,再往后选孩子的孩子,也是重复的。因为在上一个"树枝"已经选取过了。
- 如下图所示意:

class Solution {
public:
vector<int>path;
vector<vector<int>>ret;
vector<bool>used;
void backtracking(vector<int>&nums,int startIndex){
ret.push_back(path);// 注意本题收集结果的方式,每次递归都要收集结果。
if(startIndex == nums.size())return;// 这行可以不加
for(int i = startIndex;i < nums.size();i++){
// i > 0防止越界
if(i > 0 && nums[i] == nums[i-1] && used[i-1] == false)continue;// 去重
path.push_back(nums[i]);
used[i] = true;
backtracking(nums,i+1);
used[i] = false;
path.pop_back();
}
}
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
sort(nums.begin(),nums.end());// 排序,用于去重
used.resize(nums.size(),false);
backtracking(nums,0);
return ret;
}
};
- 方法2: 使用下标去重,看起来更简单些,但思想同使用used数组。此方法更贴切本题中第二张图。
class Solution {
public:
vector<int>path;
vector<vector<int>>ret;
void backtracking(vector<int>&nums,int startIndex){
ret.push_back(path);
for(int i = startIndex;i < nums.size();i++){
if(i > startIndex && nums[i] == nums[i-1])continue;// 去重
path.push_back(nums[i]);
backtracking(nums,i+1);
path.pop_back();
}
}
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
sort(nums.begin(),nums.end());// 排序,用于去重
backtracking(nums,0);
return ret;
}
};
- 方法3: 使用set去重,去重判断同理。不做过多解释。
- 有趣的一点也是重要的一点是,注意,是先判断是出现过,然后在往set里emplace,这步就相当于使用used数组中的。可以对照理解一下。是一个意思。
if(i > 0 && nums[i] == nums[i-1] && used[i-1] == false)continue;// 去重class Solution {
public:
vector<int>path;
vector<vector<int>>ret;
void backtracking(vector<int>&nums,int startIndex){
ret.push_back(path);
unordered_set<int>set;
for(int i = startIndex;i < nums.size();i++){
if(set.find(nums[i]) != set.end())continue;// 去重
path.push_back(nums[i]);
set.emplace(nums[i]);
backtracking(nums,i+1);
path.pop_back();
}
}
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
sort(nums.begin(),nums.end());// 排序,用于去重
backtracking(nums,0);
return ret;
}
};491.递增子序列
本题无法像上一题那样简单的使用used数组(bool数组)进行去重。因为并不是简单的对比前一个元素,因为前一个元素不一定就可以放进去,也就是说如果(可以的话)仍使用上面used数组去重方式,逻辑会更加复杂。- 方法1: 使用set去重,同上题使用set的方法,如下图所示,不理解就跟着走一下。
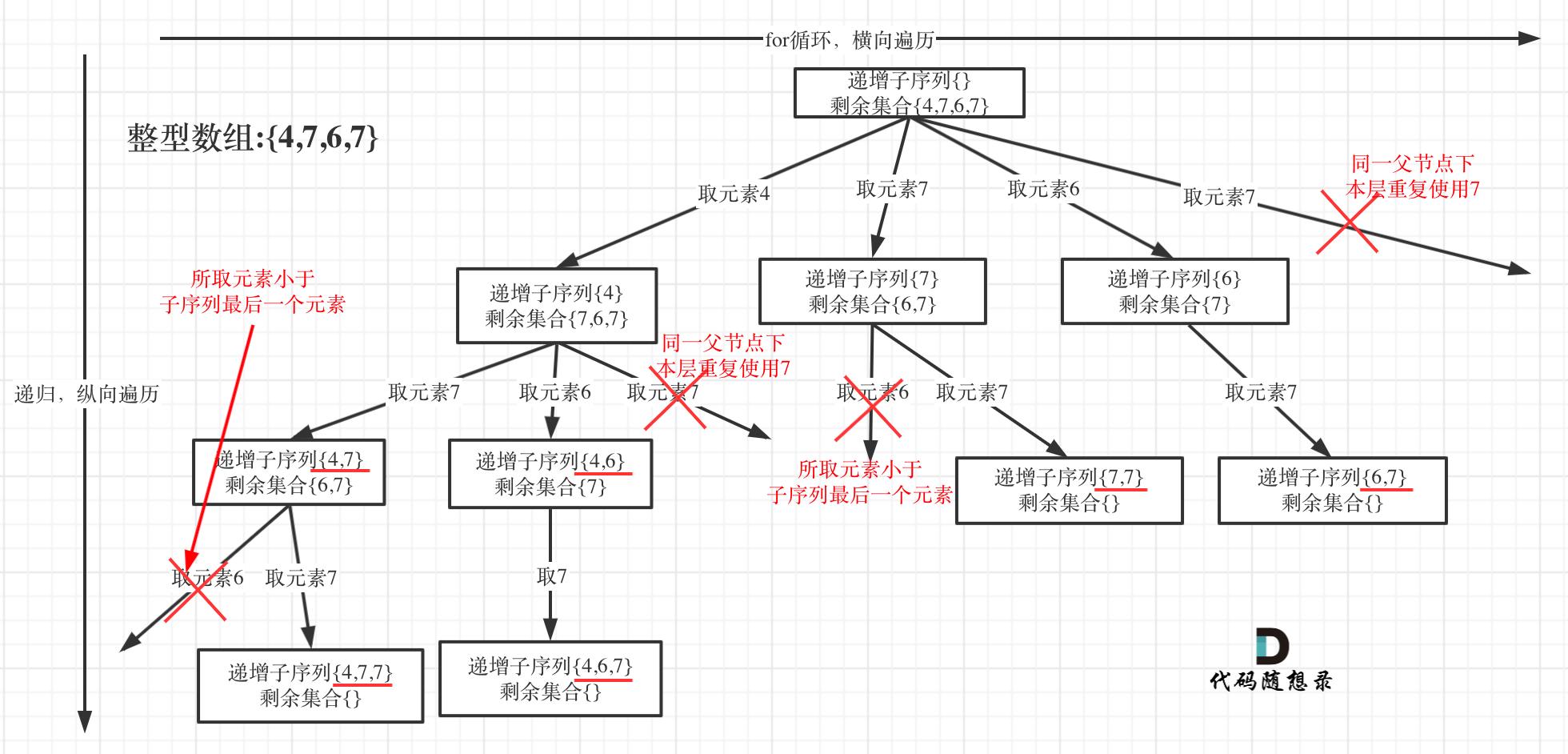
class Solution {
public:
vector<int>path;
vector<vector<int>>ret;
void backtracking(vector<int>& nums,int startIndex){
// 题目要求,递增要求,至少有两个元素
if(path.size() > 1)ret.push_back(path);
unordered_set<int>set;
for(int i = startIndex;i < nums.size();i++){
if(!path.empty() && nums[i] < path.back() ||
set.find(nums[i]) != set.end())continue;
set.emplace(nums[i]);
path.push_back(nums[i]);
backtracking(nums,i+1);
// 为什么这里不用将set中的元素弹出来,因为我们每次递归进来都会创建一个set。是局部变量。详情见上图所示
// 即每个set只负责本层。
path.pop_back();
}
}
vector<vector<int>> findSubsequences(vector<int>& nums) {
backtracking(nums,0);
return ret;
}
};
- 方法2: 使用用数组模拟哈希表来去重
class Solution {
public:
vector<int>path;
vector<vector<int>>ret;
void backtracking(vector<int>& nums,int startIndex){
// 题目要求,递增要求,至少有两个元素
if(path.size() > 1)ret.push_back(path);
int used[201] = {0};// 数据范围-100到+100
for(int i = startIndex;i < nums.size();i++){
if(!path.empty() && nums[i] < path.back() ||
used[nums[i]+100] == 1)continue;
used[nums[i]+100] = 1;
path.push_back(nums[i]);
backtracking(nums,i+1);
path.pop_back();
}
}
vector<vector<int>> findSubsequences(vector<int>& nums) {
backtracking(nums,0);
return ret;
}
};46. 全排列
相对于上面使用used数组去重,本题会更好理解些,我们使用used数组,仅仅来记录当前元素是否被使用过,而且不需要indexStart来记录每层递归开始的位置,而是每次都从头开始,从而收集所有的排列方式。
主要的一点是,不会给重复的数,以此为去重问题,见下题。
给上面的补充,写在这里,每一层,是指对应树枝的下面的每一层,不是整体的每一层。
class Solution {
public:
vector<int>path;
vector<vector<int>>ret;
vector<bool>used;// 记录当前元素是否使用过,true使用过,false没使用过
void backtracking(vector<int>& nums){
if(path.size() == nums.size()){
ret.push_back(path);
return ;
}
for(int i = 0; i < nums.size() ;i++){
if(used[i] == true)continue;// 该元素已经使用过啦
path.push_back(nums[i]);
used[i] = true;
backtracking(nums);
path.pop_back();
used[i] = false;
}
}
vector<vector<int>> permute(vector<int>& nums) {
used.resize(nums.size(),false);
backtracking(nums);
return ret;
}
};47.全排列 II
- 在上一题的基础上,给出重复的元素,需要增加去重。类似于上面求子集问题中的去重。
- 在去重逻辑中,当前元素与前一位相等,并且前一位对应used为false,去掉。
- 还是求子集问题中的去重道理。不过可以更简单的理解为,重复的数,以其为选中基准,重新排列组合出来的结果也是相同的(因为顺序固定了)。所以要去掉。——树层去重
先选中的这个数为下面树层的根。
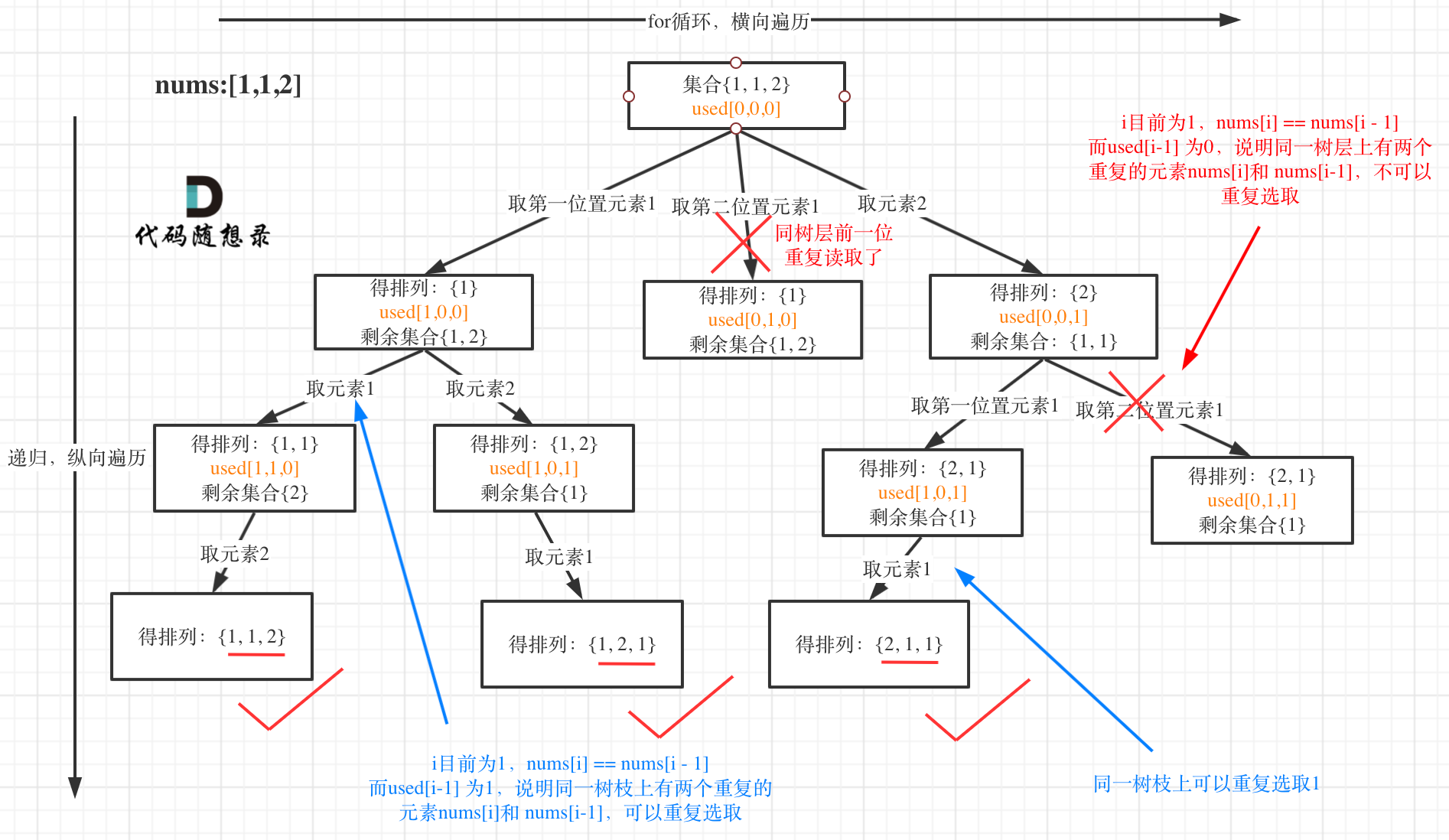
- 方法1: 树层去重
class Solution {
public:
vector<int>path;
vector<vector<int>>ret;
vector<bool>used;// 用来记录是否使用过
void backtracking(vector<int>& nums){
if(path.size() == nums.size()){
ret.push_back(path);
return ;
}
for(int i = 0; i < nums.size();i++){
if(i > 0 && nums[i] == nums[i-1] && used[i-1] == false)continue;
if(used[i] == false){// 当前元素没使用,那就选上
used[i] = true;// 使用
path.push_back(nums[i]);
backtracking(nums);// 递归
used[i] = false;// 回溯
path.pop_back();
}
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
used.resize(nums.size(),false);
sort(nums.begin(),nums.end());
backtracking(nums);
return ret;
}
};
- 方法2: 树枝去重
即,对于树的每一个树枝来说,当我们确定了一个树层的根后,下面不可以再选与其相同的子根。
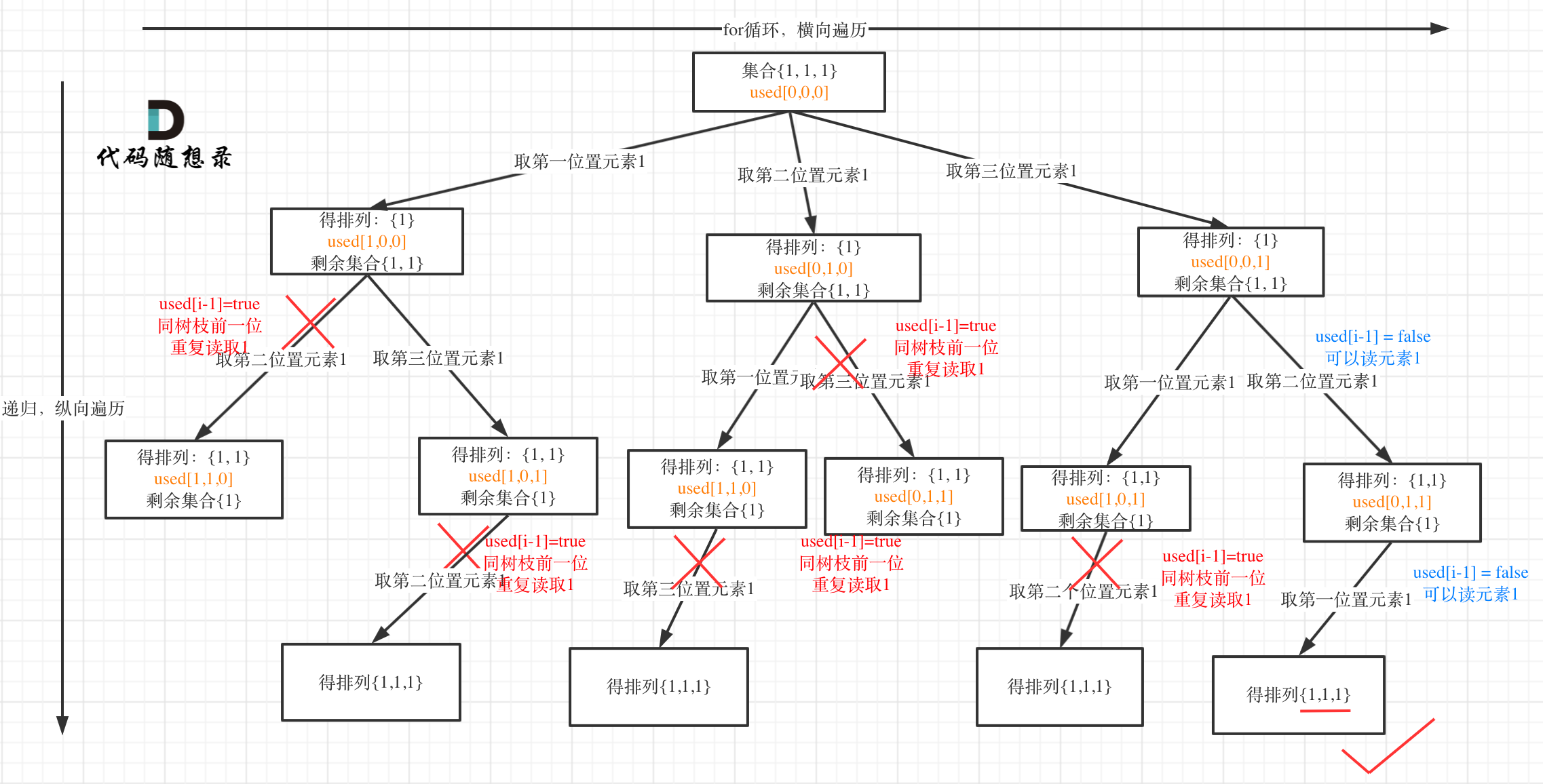
// 只需修改一步,将false改为true即可
// 如果理解了上面的我说的层的概念,这个树枝去重会很好理解。
if(i > 0 && nums[i] == nums[i-1] && used[i-1] == true)continue;
- 树层去重和树枝去重对比
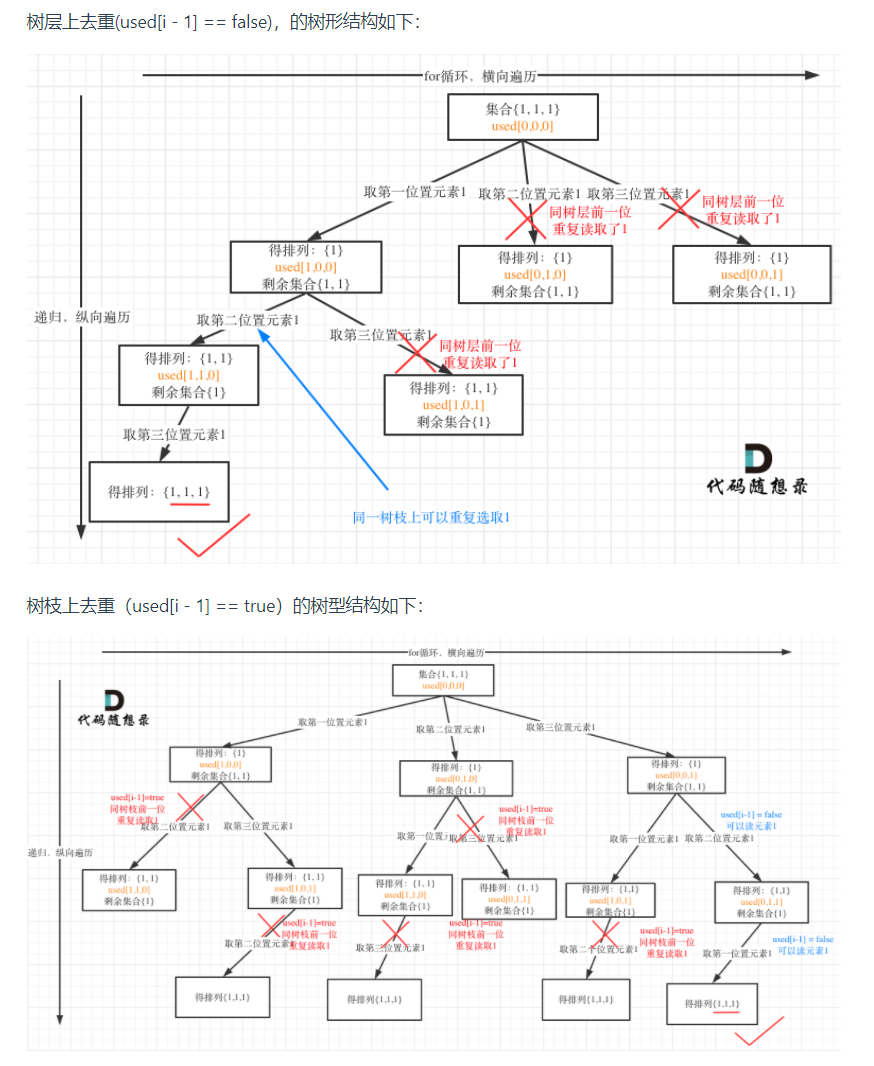
- 可以很清晰的看到,树层上对前一位去重非常彻底,效率很高,树枝上对前一位的去重虽然最后可以得到答案,但是做了很多无用搜索。
- 方法3: 使用set去重
class Solution {
public:
vector<int>path;
vector<vector<int>>ret;
vector<bool>used;// 用来记录是否使用过
void backtracking(vector<int>& nums){
if(path.size() == nums.size()){
ret.push_back(path);
return ;
}
unordered_set<int>set;
for(int i = 0; i < nums.size();i++){
if(set.find(nums[i]) != set.end())continue;// 使用过了
if(used[i] == false){// 当前元素没使用,那就选上
used[i] = true;
set.insert(nums[i]);
path.push_back(nums[i]);
backtracking(nums);
used[i] = false;
path.pop_back();
}
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
used.resize(nums.size(),false);
sort(nums.begin(),nums.end());
backtracking(nums);
return ret;
}
};
- 注意:
- 使用set去重的版本相对于used数组的版本效率会低很多。
- 因为频繁的对unordered_set进行insert操作,unordered_set需要做哈希映射(也就是把key通过hash function映射为唯一的哈希值)相对费时间,而且insert的时候其底层的符号表也要做相应的扩充,也是费时的。
332. 重新安排行程
- 就是看能不能把所有票都用上。走完全程。
class Solution {
public:
// 某一个机场可以到达的机场都有哪些,航班次数为这样的航班有几个。
// 出发机场,<到达机场,航班次数>
unordered_map<string,map<string,int>>targets;
vector<string>ret;// 收集结果,沿途经过的机场数
bool backtracking(int ticketNum){
// ret.size()当前经过的机场数量 == 航班数量+1
// 就是将所有票都用上了,终止。
if(ret.size() == ticketNum + 1)return true;// 当前票都使用完毕
//每次遍历的时候拿到上一个降落的机场,遍历这个机场接下来可以往哪飞
for(pair<const string,int>& target : targets[ret[ret.size()-1]]){// 注意传引用,修改second值,const-因为map中的key不可修改。
if(target.second > 0){//
ret.push_back(target.first);
target.second--;
if(backtracking(ticketNum))return true;// 找到了终止,就不pop出来了
ret.pop_back();// 回溯
target.second++;
}
}
return false;
}
vector<string> findItinerary(vector<vector<string>>& tickets) {
targets.clear();
for(const vector<string>& vec: tickets){// 记录映射关系-当前机场都能到哪个机场,能到达几次
targets[vec[0]][vec[1]]++;// 计数,使用了当前票--,避免死循环。
}
ret.push_back("JFK");// 起始机场
backtracking(tickets.size());
return ret;
}
};第51题. N皇后
- 时间复杂度: $O(n!)$
- 空间复杂度: $O(n)$,和子集问题同理
- 皇后们的要求
- 不能同行
- 不能同列
- 不能同斜线,45 & 135
class Solution {
public:
vector<vector<string>>ret;
vector<string>chess_borad;
void backtracking(int n,int row){// n为棋盘大小,row为当前到第几行
if(row == n){// 每行都确定了皇后的位置
ret.push_back(chess_borad);
return ;
}
for(int col = 0; col < n;col++){
if(isValid(row,col,n)){// 当前位置合法
chess_borad[row][col] = 'Q';// 放置皇后
backtracking(n,row+1);
chess_borad[row][col] = '.';// 撤销皇后
}
}
}
// 判断当前位置放入皇后,是否合法
bool isValid(int row,int col,int n){
// 检查列
for(int i = 0; i < row;i++){
if(chess_borad[i][col] == 'Q')return false;
}
// 为什么这里没有单独检查行呢,因为递归的时候就是在调整行,递归一下,切换一下行。
// 45度——也就是往右上判断,为什么不用判断左下判断,因为还没到下面的行。
// 135度判断同理
for(int i = row - 1,j = col + 1 ;i >=0 && j < n;i--,j++){
if(chess_borad[i][j] == 'Q')return false;
}
for(int i = row - 1,j = col - 1; i >= 0 && j >= 0;i--,j--){
if(chess_borad[i][j] == 'Q')return false;
}
return true;
}
vector<vector<string>> solveNQueens(int n) {
chess_borad.resize(n,string(n,'.'));
backtracking(n,0);
return ret;
}
};37. 解数独
时间复杂度: $O(9^m)$,m是'.'的数目
空间复杂度: $O(n^2)$,递归的深度是$O(n^2)$
判断棋盘是否合法
- 同行是否重复
- 同列是否重复
- 9宫格里是否重复
就是一个萝卜一个坑,理论上来说有几个空白位置就会递归几层。递归只是为了找到坑位,不会再向后移动,搜寻别的坑。详见下方注释。
class Solution {
public:
bool isValid(int row,int col,char val,vector<vector<char>> &board){
for(int i = 0; i < 9;i++){// 检查同行是否有重复
if(board[row][i] == val)return false;
}
for(int i = 0;i < 9;i++){// 检查同列是否有重复
if(board[i][col] == val)return false;
}
// 检查九宫格内是否有重复
int startRow = (row / 3)*3;//定位每个九宫格左上角位置
int startCol = (col / 3)*3;
for(int i = startRow;i < startRow + 3;i++){
for(int j = startCol;j < startCol + 3;j++){
if(board[i][j] == val)return false;
}
}
return true;
}
bool backtracking(vector<vector<char>>& board){
// 有趣的一点,我们发现在这里并没有控制下标访问,因为我们将某个空白位置放上了数字,board[i][j]就不为'.'啦,递归时就不会覆盖上一层所放的位置
// 递归的时候会不断找到空的位置,尝试放入合法的数。也就是说每次层递归,都确定一个空位置被放入一个合法的数。
// 就是一个萝卜一个坑,理论上来说有几个空白位置就会递归几层。递归只是为了找到坑位,不会再向后移动,搜寻别的坑。
// 当某一层递归中,某一个空白放哪个数字都不行,return false,回溯,尝试将上一层所放置的位置换成别的,继续调整。
for(int i = 0; i < 9;i++){
for(int j = 0; j < 9;j++){
if(board[i][j] == '.'){// 是空白
for(char k = '1' ;k <= '9';k++){// 遍历,放置合适的数字
if(isValid(i,j,k,board)){// 可以放
board[i][j] = k;
if(backtracking(board))return true;// 可以了就终止
board[i][j] = '.';
}
}
return false;// 九个数都是了,放哪个都不行,return false
}
}
}
return true;
}
void solveSudoku(vector<vector<char>>& board) {
backtracking(board);
}
};
- 这个回溯拖得时间还是比较长了,抓紧抓紧!Orz
评论区