

About
Lab
Task #1 - Extendible Hash Table
详见——【CMU15-445 FALL 2022】Project #1 - Extendable Hashing
如果链接失效,请查看当前平台我之前发布的文章。
Task #2 - LRU-K Replacement Policy
Concept
相关参考
什么是LRU?
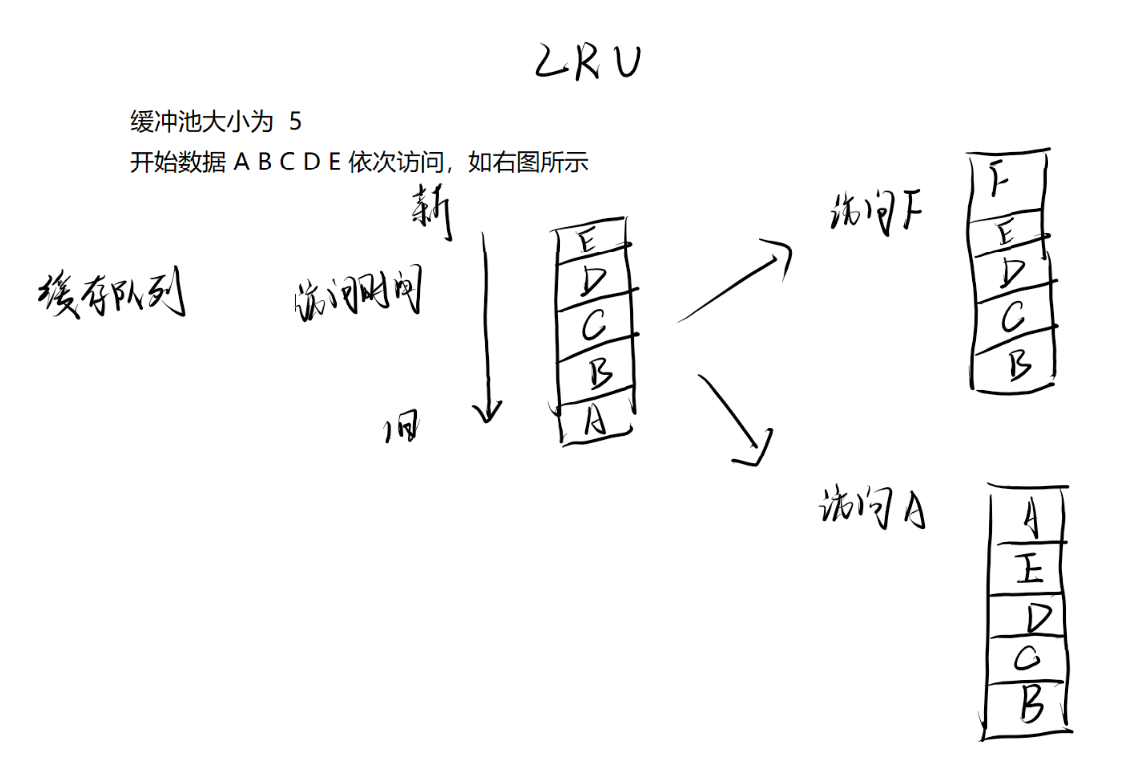
是一种缓存淘汰机制,全称为Least Recently Used,即最近最少使用算法。
当缓存满了的时候,会将当前最久没被使用过的元素从缓存中踢出,给新进来的数据腾出空间。
详见下示例
LRU缓存污染问题?
因为LRU算法被将数据添加到缓存中的条件是最近访问一次即可, 如果当前有大量数据被访问,将缓存中我们高频访问的数据挤了出去,而这些数据在很长的一段事件内斗不会在被访问了,这就造成了缓存污染。
什么是LRU-K替换策略?
在LRU基础上增加了K次的限制,为了解决缓存污染。
相比与LRU算法,LRU-K需要两个队列来统计数据的访问,一个历史访问队列和一个缓存队列,只有当数据被访问了K次,才会被加入到缓存队列中。
未到达K次访问的,按照LRU,FIFO淘汰,即最久没被访问过的先淘汰,如上面LRU图所示。
但是在本实验的代码实现中,我们并不需要这样,对于未达到进入缓存队列次数的,仅仅更新访问次数即可, 无需变更在历史队列中的位置。
补充
可以先做一下leetcode的这道题——146. LRU 缓存
使用list存,unordered_map存list结点,用于快速查找定位。
Member
Member Var
curr size
可以驱逐出的帧的数量
replacer size
frame_ id _的取值范围
k_
进入缓存队列的访问次数限制
std::mutex latch_;
互斥锁
下面是一些额外的辅助变量(不是必须得,需要根据你的具体实现来选择。)
m_isevictable;
帧是否可被驱逐
m_accesscount
帧的访问次数记录
m_cachelist && m_cache map
缓存"队列"(实际上是链表,哈希表是为了快速定位链表中的指定结点)
m_historylist && m_historymap
历史"队列"。
Member Function
*auto Evict(frame_id_t frame_id) -> bool;**
尝试驱逐帧。
如果有可驱逐的,将驱逐帧存储到参数frame_id中,并返回true
反之,返回false
先从历史队列中尝试驱逐,然后再从缓存队列中尝试驱逐。
void RecordAccess(frame_id_t frame_id) ;
记录当前帧的访问。
根据出现的次数进行之后的操作。注意更新当前帧的访问次数。
等于k_次,即可将该帧从历史队列中放入缓存队列中,放在最新访问的位置(即,头或尾,这取决于你的实现,哪边是最久访问,哪边是最新访问。)
大于k_次,将更新在缓存队列中的位置,即放在最新访问的位置。
小于k_次,注意: 如果是第一次出现,
void SetEvictable(frame_id_t frame_id, bool set_evictable);
设置可驱逐标志。
判断给定frame_id是否合法 & 存在。
根据原来的状态与要变更的状态,更新当前可驱逐帧的数量。
最后更新该帧状态。
void Remove(frame_id_t frame_id);
删除指定帧的访问记录。
判断给定frame_id是否合法 & 存在。
判断是否是可驱逐的,不可驱逐的,也不能删除。
根据该帧的访问次数,判断从历史队列中删除还是在缓存队列中删除。
更新可驱逐帧的数量。
auto LRUKReplacer::Size() -> size_t;
返回当前可回收帧的数量。
Example
下面做一个简单示例
①先依次访问A B C D E
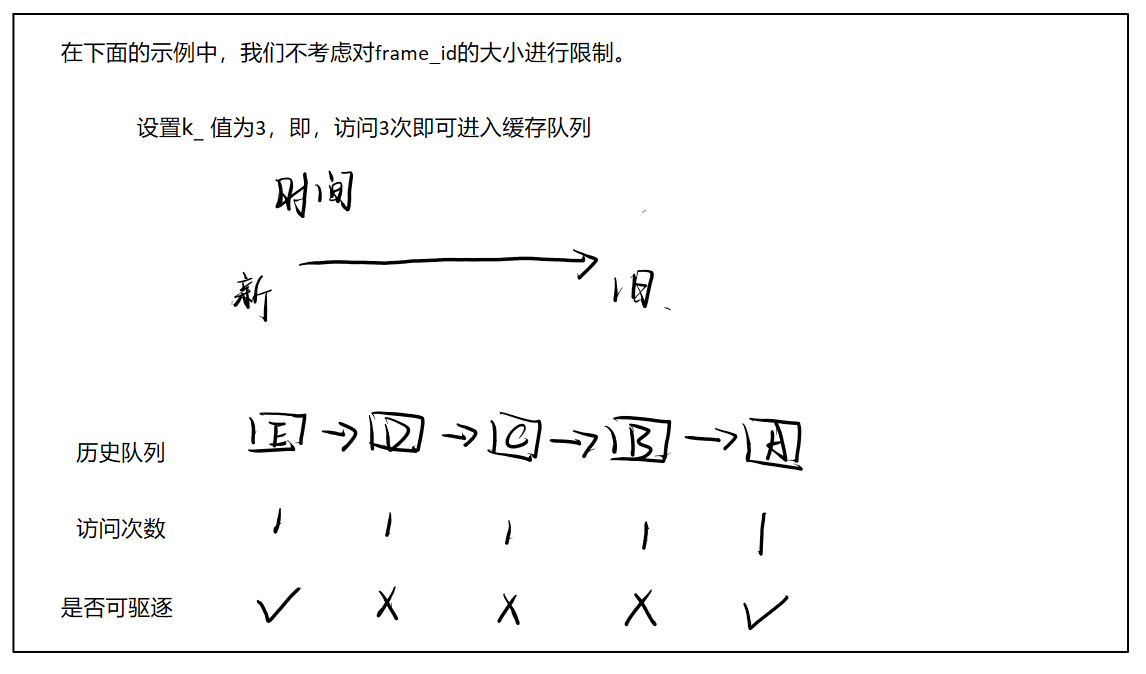
②再访问 A 2次

③再访问 D 2次
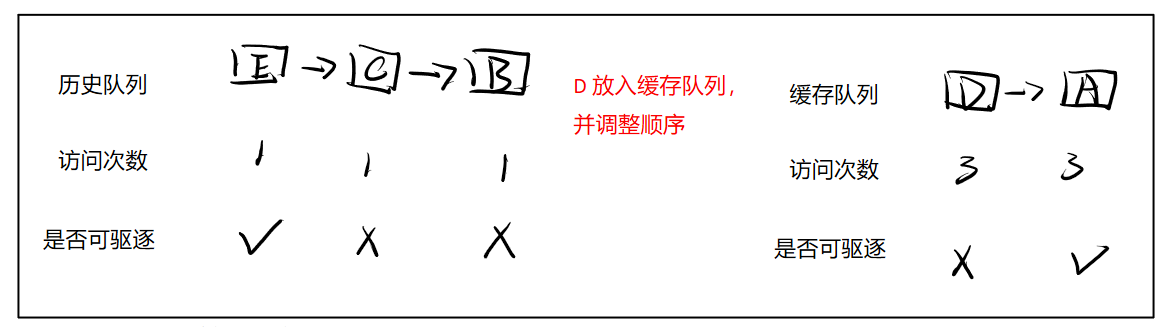
④再访问 B 1次
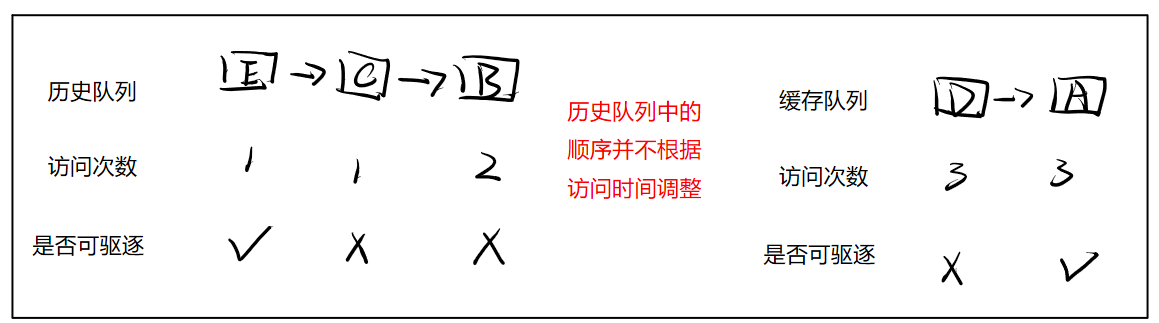
⑤再访问 A 1次
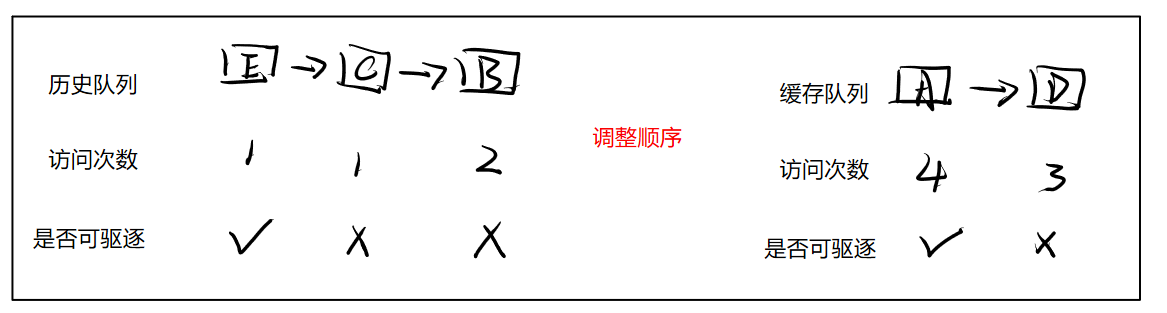
⑥尝试驱逐

⑦尝试驱逐

Task #3 - Buffer Pool Manager Instance
Concept
相关视频
buffer pool的目的
缓存池为了弥补磁盘和内存之间访问速度的巨大差异,提高数据库性能。
把硬盘上的文件页读到内存池中,交够执行器进行后续的操作
内存与硬盘
Dircetory 几号页在文件的什么位置
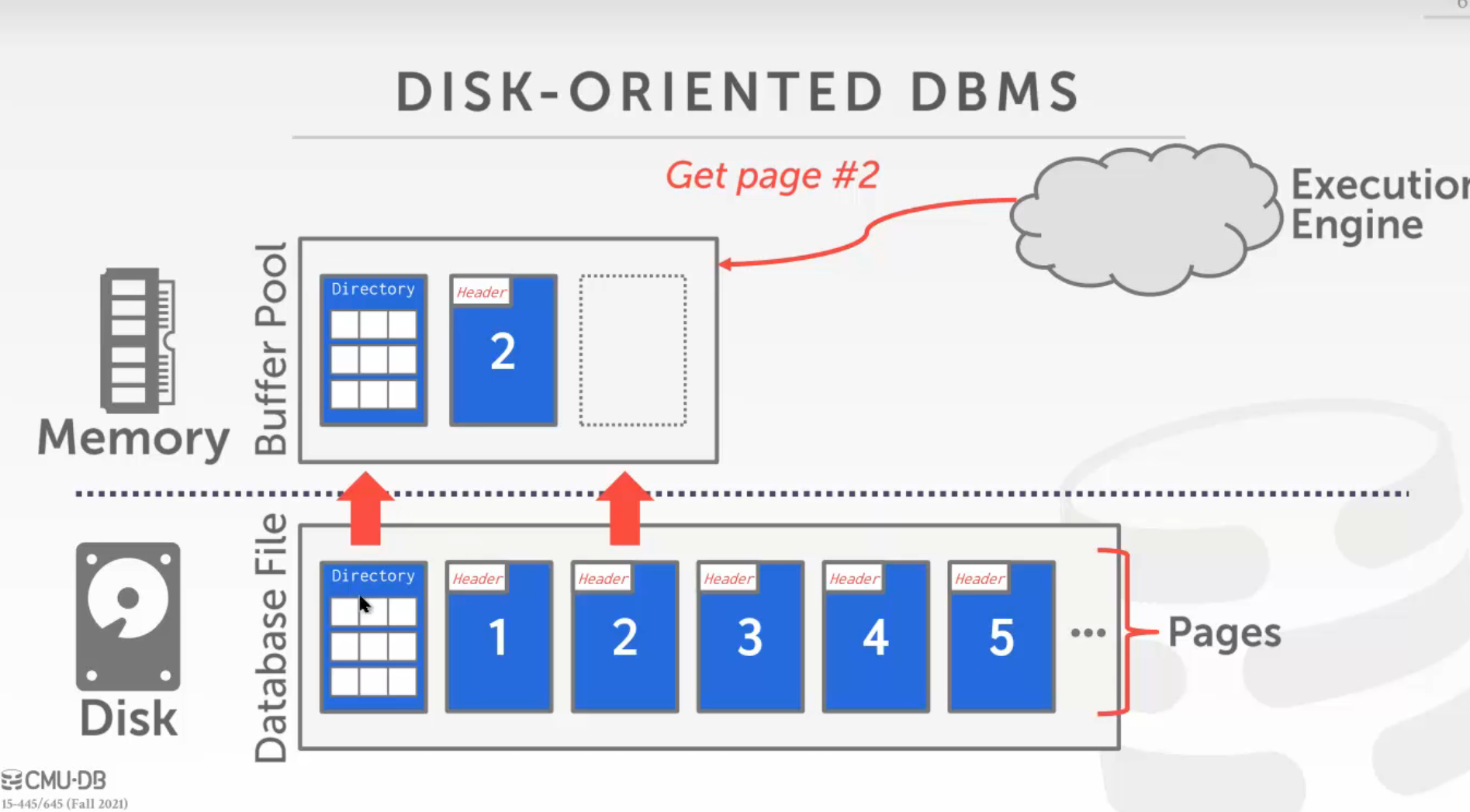
缓存池的组成
page_table的key为物理存储页对应的value是缓存池中的页。
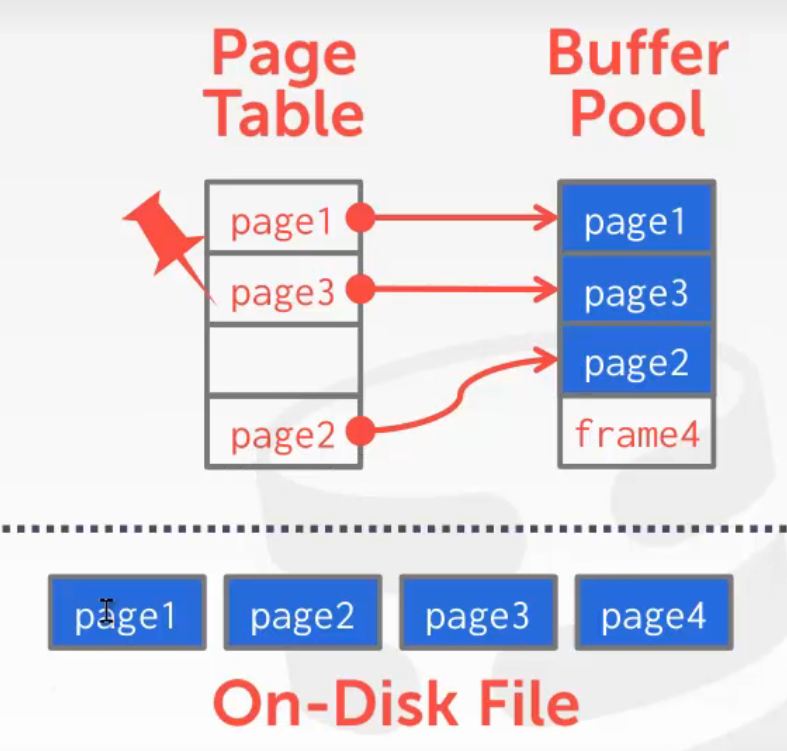
磁盘上叫page,缓存池中叫frame
使用ExtendebleHashTable将page_id映射到frame_id
使用LRUKReplacer类跟踪页面对象何时被访问,以便在必须释放一个帧以腾出空间从磁盘复制新的物理页面时,它可以决定驱逐哪个对象。
page和frame是什么关系?
frame_id 与page_id
page_id是所对应的物理页id,frame_id是对应的内存中的缓冲池的页面id
free_list: 缓冲池中空闲的frame,如果没有可驱逐的,无法创建新页面。有可驱逐的,再检查是否有空闲的frame。
pages_数组中的索引即frameid,每个Page即pages[i]存储frame_id对应的page_id等信息。
Members
Member var
poolsize
缓冲池中的页数,即pages_的最大大小。
next_pageid
要分配的下一个page_id。
bucketsize
可扩展哈希中的每个桶的最大元素容量。
pages_
缓冲池页数组,fame_id即为其下标索引。
pagetable
用于跟踪缓冲池页面的页表。用于查询是否存在指定id
replacer_
替换器,用于替换的未固定页面。
freelist
空闲页面链表。
latch_
并发锁。
Member Function
auto NewPgImp(page_id_t page_id) -> Page override;
功能
在缓冲池中创建新页面。将 page_id 设置为新页面的 id。
首先,如果所有框架当前都在使用且不可逐出,直接返回nullptr
之后,检查空闲列表中是否有可用的。
没有则尝试开始驱逐,即没被引用的。
并且这个要注意被驱逐的是否有脏页标记,有则写回硬盘。最后重置该块内存。
同时更新相关信息,如pages_信息,LRU-K信息(添加访问记录,设置为不可驱逐),以及在哈希表中的映射信息。
参数
page_id: 本次创建出的页面的id
返回
如果无法创建新页面,则return nullptr,否则指向新页面的指针。
*auto FetchPgImp(page_id_t page_id) -> Page override;**
功能
从缓冲池拿一个页面。
如果找到这个page_id对应的frame_id
返回对应的page地址
没找到则创建
检查是否有可驱逐页面,如果所有框架当前都在使用且不可逐出,直接返回nullptr
之后,检查空闲列表中是否有可用的。
没有则尝试开始驱逐,即没被引用的。
并这个要注意被驱逐的是否有脏页标记,有则写回硬盘。最后重置该块内存。
调用diskmanager->ReadPage()从磁盘读取页面,
同时更新相关信息,如pages_信息,LRU-K信息(添加访问记录,设置为不可驱逐),以及在哈希表中的映射信息。
参数
指定的page_id,即frame_id对应的物理页id
返回值
找到返回指向指定页面的指针,反之尝试创建,无法创建返回nullptr,否则返回指向新页面的指针。
auto UnpinPgImp(page_id_t page_id, bool is_dirty) -> bool override;
从缓冲池中取消固定目标页。
如果page_id不在缓冲池中或其引用数已为 0,则返回 false。
递减页面的引用数。如果引用数达到 0,设置该frame可以被驱逐。
注意: 如果传进来的参数is_dirty为真,才赋值。
参数
要取消固定的页面的page_id ID
脏页标记is_dirty
返回
如果页面不在此调用中或其引脚计数为 <= 0,则为 false,否则为 true
auto FlushPgImp(page_id_t page_id) -> bool override;
功能
将目标页刷新到磁盘。
使用 DiskManager::WritePage() 方法将页面刷新到磁盘,而不考虑脏标志。
刷新后取消设置页面的脏标志。
参数
page_id要刷新的页面的 ID
不能是INVALID_PAGE_ID
返回
如果该page_id为INVALID_PAGE_ID,或者在页表中找不到该页,返回false,否则返回 true
void FlushAllPgsImp() override;
功能
将缓冲池中的所有页面刷新到磁盘。
auto DeletePgImp(page_id_t page_id) -> bool override;
功能
从缓冲池中删除页面。
如果page_id不在缓冲池中,则不执行任何操作并返回 true。如果页面已固定且无法删除(即被引用),请立即返回 false。
删除在哈希表中的映射记录,删除LRU-K替换器中的记录,重置对应的page信息,将该frame_id放到空闲队列中。
参数
page_id:要删除的页面的ID
返回值
如果页面存在但无法删除,则为 false。
如果页面不存在或删除成功,则为 true。
Complement
scoped_lock
C++17新特性,RAII机制的并发编程技巧
构造时获取锁,析构时释放锁。
std::scoped_lock<std::mutex> lock(latch_);enable_if & constexpr if
enable_if
以下内容来源于ChatGPT
C++的enable_if是一个模板元编程工具,用于在编译时根据条件来选择是否启用或禁用特定的函数模板。它可以与函数模板、类模板和模板别名一起使用。
enable_if通过在函数模板的返回类型中使用模板参数作为条件来工作。
当条件为true时,返回类型有效并启用函数模板;
当条件为false时,enable_if会导致编译器选择其他重载或者删除该函数模板。
示例如下所示:
#include <iostream>
#include <type_traits>
// 函数模板,仅当T是整数类型时才可用
template <typename T>
typename std::enable_if<std::is_integral<T>::value, void>::type
printNumber(T number) {
std::cout << "Number: " << number << std::endl;
}
// 函数模板,仅当T是浮点类型时才可用
template <typename T>
typename std::enable_if<std::is_floating_point<T>::value, void>::type
printNumber(T number) {
std::cout << "Number: " << number << std::endl;
}
int main() {
printNumber(10); // 调用第一个printNumber模板
printNumber(3.14); // 调用第二个printNumber模板
printNumber("Hello"); // 错误,没有匹配的模板可用
return 0;
}在上面的示例中,我们定义了两个重载的函数模板printNumber,分别处理整数和浮点数类型。enable_if用于在编译时选择正确的模板。
对于整数类型,std::is_integral::value为true,因此第一个函数模板会被选择。
对于浮点数类型,std::is_floating_point::value为true,因此第二个函数模板会被选择。
如果我们尝试传递一个非数字类型(如字符串),则会导致编译错误,因为没有匹配的模板可用。
enable_if还可以与其他模板元编程技术结合使用,例如std::enable_if_t、std::conditional等,以实现更复杂的条件选择和类型推导。
constexpr if
以下内容来源于ChatGPT
constexpr if 是 C++17 中引入的编译时条件分支语句,用于在编译时根据条件选择是否编译特定的代码块。它允许根据常量表达式的结果来进行静态分支,以在编译时执行不同的代码路径。
constexpr if 在编译时进行条件分支,并且不满足条件的分支将不会被编译。这意味着,不满足条件的代码块不会生成任何编译产物,包括生成的机器指令和相关的类型和符号。
constexpr if 的语法结构如下:
if constexpr (条件)
{
// 编译时满足条件时执行的代码块
}
else
{
// 编译时条件不满足时执行的代码块
}以下是一个使用 constexpr if 的示例:
#include <iostream>
template<typename T>
void printValue(T value)
{
if constexpr (std::is_integral<T>::value)
{
std::cout << "Integral value: " << value << std::endl;
}
else if constexpr (std::is_floating_point<T>::value)
{
std::cout << "Floating point value: " << value << std::endl;
}
else
{
std::cout << "Other type value." << std::endl;
}
}
int main()
{
printValue(42); // 编译时选择第一个代码块
printValue(3.14); // 编译时选择第二个代码块
printValue("Hello"); // 编译时选择第三个代码块
return 0;
}在上述示例中,printValue 函数根据传递的值的类型使用 constexpr if 进行条件判断。
如果类型是整数类型,则选择第一个代码块输出整数值;
如果类型是浮点类型,则选择第二个代码块输出浮点值;
否则选择第三个代码块输出其他类型的值。
在编译时,只有符合条件的代码块会被编译,而不满足条件的代码块不会产生任何代码。
constexpr if 的好处是它可以在编译时进行静态分支,避免了运行时的开销。它还可以用于编写更加通用和灵活的模板代码,根据不同的条件生成不同的代码逻辑。
different
constexpr if和enable if是两个不同的C++特性,用于在编译时根据条件选择代码路径,但它们在语法和使用上有一些区别。
语法差异:
constexpr if是C++17引入的新特性,使用关键字if constexpr。它允许在代码块中使用条件语句,并根据条件在编译时选择性地编译不同的代码路径。enable if是一个模板元编程工具,使用typename std::enable_if<condition, T>::type的形式将其应用于模板参数或函数返回类型。它用于在编译时基于类型或条件启用或禁用函数模板。
应用范围:
constexpr if可以在任何函数中使用,包括普通函数和模板函数。它允许对常量表达式进行静态分支,并且可以在编译时决定不同的代码路径。enable if通常与模板函数一起使用,用于在编译时根据类型或条件启用或禁用特定的模板函数。它主要用于模板元编程和SFINAE(Substitution Failure Is Not An Error)技术。
使用场景:
constexpr if适用于需要在编译时进行条件分支的情况,例如根据类型或常量表达式的值执行不同的代码路径。enable if适用于需要在模板函数中根据类型或条件启用或禁用特定实例化的情况。它通常用于模板函数的重载和模板参数的限制。
总的来说,
constexpr if和enable if是两个不同的特性,适用于不同的场景。constexpr if提供了在编译时进行条件分支的能力,而enable if是用于模板元编程和SFINAE技术的工具,用于在编译时选择特定的模板函数或模板参数。
补充
Last
P1 拖了好久才完成,在公司实习时弄了一些,之后回学校实训弄了一些,最后还是参考了别人的代码,后面的内容要加速了。
评论区